





Tensorflow ResNet-50 Benchmark
Tensorflow™ ResNet-50-Benchmark
LeaderGPU® ist ein Dienst, der seit geraumer Zeit mit ernsten Absichten in den Markt für GPU-Computing einsteigt. Die Geschwindigkeit der Berechnungen für das ResNet-50-Modell in LeaderGPU® ist 2,5 Mal schneller im Vergleich zu Google Cloud und 2,9 Mal schneller im Vergleich zu AWS (die Daten werden für ein Beispiel mit 8x GTX 1080 im Vergleich zu 8x Tesla® K80 bereitgestellt). Die Kosten für die Miete der GPU pro Minute in LeaderGPU® beginnen bei nur 0,02 Euro, was mehr als viermal niedriger ist als die Kosten für die Miete in Google Cloud und mehr als fünfmal niedriger als die Kosten in AWS (Stand: 7. Juli 207).
Im Laufe dieses Artikels werden wir das ResNet-50-Modell in so beliebten Diensten wie LeaderGPU®, AWS und Google Cloud testen. Sie werden in der Praxis sehen können, warum LeaderGPU® die dargestellten Wettbewerber deutlich übertrifft.
Alle Tests wurden mit Python 3.5 und Tensorflow-gpu 1.2 auf Maschinen mit GTX 1080, GTX 1080 TI und Tesla® P 100 mit installiertem CentOS 7 Betriebssystem und CUDA® 8.0 Bibliothek durchgeführt.
Die folgenden Befehle wurden verwendet, um den Test auszuführen:
git clone https://github.com/tensorflow/benchmarks.gitpython3.5 benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --num_gpus=?(Number of cards on the server) --model resnet50 --batch_size 32 (64, 128, 256, 512)GTX 1080-Instanzen
Für den ersten Test verwenden wir Instanzen mit der GTX 1080. Die Daten der Testumgebung (mit den Losgrößen 32 und 64) finden Sie unten:
- Instanztypen: 2x GTX 1080, 4x GTX 1080, 8x GTX 1080
- Betriebssystem: CentOS 7
- CUDA® / cuDNN: 8.0 / 5.1
- TensorFlow™ GitHub-Hash: b1e174e
- Benchmark GitHub-Hash: 9165a70
- Befehl: # python3.5 benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --num_gpus=2 (4,8) --model resnet50 --batch_size 32 (optional 64, 128,256, 512)
- Modell: ResNet50
- Datum der Prüfung: Juni 2017
Die Testergebnisse sind im folgenden Diagramm dargestellt:

GTX 1080TI-Instanzen
Der nächste Schritt ist das Testen von Instanzen mit der GTX 1080 Ti. Die Daten der Testumgebung (mit den Losgrößen 32, 64 und 128) sind unten aufgeführt:
- Instanztypen: ltbv21, ltbv18
- GPU: 2x GTX 1080TI, 4x GTX 1080TI
- Betriebssystem: CentOS 7
- CUDA® / cuDNN: 8.0 / 5.1
- TensorFlow™ GitHub-Hash: b1e174e
- Benchmark GitHub-Hash: 9165a70
- Befehl: # python3.5 benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --num_gpus=2 (4) --model resnet50 --batch_size 32 (optional 64, 128,256, 512)
- Modell: ResNet50
- Datum der Prüfung: Juni 2017
Die Testergebnisse sind im folgenden Diagramm dargestellt:

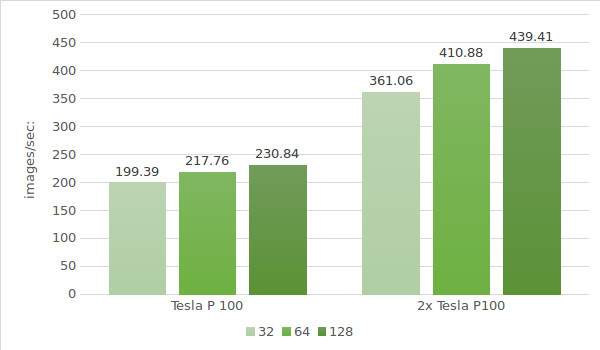
Tesla® P100-Instanz
Der letzte Schritt ist das Testen von Instanzen mit Tesla® P100. Die Daten der Testumgebung sind unten aufgeführt (mit den Losgrößen 32, 64 und 128):
- Instanztyp: 2x NVIDIA® Tesla® P100
- Betriebssystem: CentOS 7
- CUDA® / cuDNN: 8.0 / 5.1
- TensorFlow™ GitHub-Hash: b1e174e
- Benchmark GitHub-Hash: 9165a70
- Befehl: # python3.5 benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --num_gpus=2 --model resnet50 --batch_size 32 (optional 64, 128, 256, 512)
- Modell: ResNet50
- Datum der Prüfung: Juni 2017
Die Testergebnisse sind im folgenden Diagramm dargestellt:
Die folgende Tabelle zeigt die Resnet50-Testergebnisse für Google Cloud und AWS (Losgröße 64):
| GPU | Google-Wolke | AWS |
|---|---|---|
| 1x Tesla® K80 | 51.9 | 51.5 |
| 2x Tesla® K80 | 99 | 98 |
| 4x Tesla® K80 | 195 | 195 |
| 8x Tesla® K80 | 387 | 384 |
* Die bereitgestellten Daten stammen aus den folgenden Quellen:
https://www.tensorflow.org/performance/benchmarks#details_for_google_compute_engine_nvidia_tesla_k80 https://www.tensorflow.org/performance/benchmarks#details_for_amazon_ec2_nvidia_tesla_k80
Berechnen wir die Kosten und die Verarbeitungszeit für 1.000.000 Bilder auf jedem LeaderGPU®-, AWS- und Google-Rechner. Die Zählung ist mit einer Stapelgröße von 64 für alle Maschinen verfügbar.
| GPU | Anzahl der Bilder | Zeit | Preis (pro Minute) | Gesamtkosten |
|---|---|---|---|---|
| 2x GTX 1080 | 1000000 | 64m 15sec | 0,02 € | 1,29 € |
| 4x GTX 1080 | 1000000 | 34m 17sec | 0,03 € | 1,03 € |
| 8x GTX 1080 | 1000000 | 17m 32sec | 0,09 € | 1,58 € |
| 4x GTX 1080TI | 1000000 | 23m 34sec | 0,04 € | 0,94 € |
| 2х Tesla® P100 | 1000000 | 40m 33sec | 0,08 € | 3,24 € |
| 8x Tesla® K80 Google-Wolke | 1000000 | 43m 3sec | 0,0825 €** | 3,55 € |
| 8x Tesla® K80 AWS | 1000000 | 43m 24sec | 0,107 € | 4,64 € |
** Der Google-Cloud-Dienst bietet keine minutenbasierten Zahlungspläne an. Die Berechnung der Kosten pro Minute basiert auf dem Stundenpreis ($ 5,645).
Wie aus der Tabelle zu entnehmen ist, ist die Bildverarbeitungsgeschwindigkeit im Modell ResNet-50 mit 8x GTX 1080 von LeaderGPU® am höchsten, während:
- Die anfänglichen Mietkosten bei LeaderGPU® beginnen bei nur 1,28 €, was etwa 2,77 Mal niedriger ist als bei den Instanzen von 8x Tesla® K80 von Google Cloud und etwa 4,38 Mal niedriger als bei den Instanzen von 8x Tesla® K80 von Google AWS;
- Die Verarbeitungszeit betrug 17 Minuten und 32 Sekunden, was 2,5 Mal schneller ist als bei den 8x Tesla® K80-Instanzen von Google Cloud und 2,49 Mal schneller als bei den 8x Tesla® K80-Instanzen von Google AWS.
LeaderGPU® übertrifft seine Konkurrenten sowohl in Bezug auf die Verfügbarkeit des Dienstes als auch auf die Geschwindigkeit der Bildverarbeitung deutlich. Mieten Sie eine GPU mit einer minutenweisen Zahlung in LeaderGPU®, um verschiedene Aufgaben in kürzester Zeit zu lösen!
LEGAL WARNING:
PLEASE READ THE LICENSE FOR CUSTOMER USE OF NVIDIA® GEFORCE® SOFTWARE CAREFULLY BEFORE AGREEING TO IT, AND MAKE SURE YOU USE THE SOFTWARE IN ACCORDANCE WITH THE LICENSE, THE MOST IMPORTANT PROVISION IN THIS RESPECT BEING THE FOLLOWING LIMITATION OF USE OF THE SOFTWARE IN DATACENTERS:
«No Datacenter Deployment. The SOFTWARE is not licensed for datacenter deployment, except that blockchain processing in a datacenter is permitted.»
Customer may use the LeaderGPU® Services for blockchain processing.
BY AGREEING TO THE LICENSE AND DOWNLOADING THE SOFTWARE YOU GUARANTEE THAT YOU WILL MAKE CORRECT USE OF THE SOFTWARE AND YOU AGREE TO INDEMNIFY AND HOLD US HARMLESS FROM ANY CLAIMS, DAMAGES OR LOSSES RESULTING FROM ANY INCORRECT USE OF THE SOFTWARE BY YOU.
Aktualisiert: 04.01.2026
Veröffentlicht: 07.12.2017