





Zusammenfassung der Ergebnisse der Testmodelle für die Klassifizierung von Bildern
LeaderGPU® ist ein neuer Akteur auf dem GPU-Computing-Markt, der die Spielregeln neu definieren will. Derzeit wird der Markt für GPU-Computing von mehreren großen Unternehmen wie AWS, Google Cloud usw. beherrscht. Doch als großer Akteur hat man nicht automatisch das beste Marktangebot. Im Gegensatz zu AWS und Google Cloud umfasst das LeaderGPU®-Projekt physische Server und keine VPS, bei denen die Hardware-Ressourcen von mehreren Dutzend Benutzern gemeinsam genutzt werden können. In der nachstehenden Tabelle werden die Kosten für die Verarbeitung von 500.000 Bildern für das Inception V3-Modell durch verschiedene Anbieter verglichen:
| Modell | GPU | Anbieter | Anzahl der Bilder | Zeit | Preis (pro Minute) | Gesamtkosten |
|---|---|---|---|---|---|---|
| Inception V3 | 8x K80 | Google cloud | 500000 | 36m 43sec | €0.0825* | €3.02 |
| Inception V3 | 8x K80 | AWS | 500000 | 36m 14sec | €0.107 | €3.87 |
| Inception V3 | 8x GTX 1080 | LeaderGPU | 500000 | 12m 9sec | €0.11 | €1.34 |
Die Tabelle zeigt, dass LeaderGPU® nicht nur 300 % schneller als seine Konkurrenten ist, sondern auch um mindestens 29 % kostengünstiger als Google Cloud und AWS.
Die Tests wurden auf den LeaderGPU®-Rechnersystemen durchgeführt. Für die Bewertung der Konkurrenten haben wir die Ergebnisse der Tests von Google- und AWS-Instanzen verwendet. Die Tests wurden mit synthetischen Daten der folgenden Netzmodelle durchgeführt: ResNet-50, ResNet-152, VGG16 und AlexNet. Am Ende dieses Artikels finden Sie die Ergebnisse von Tests anderer Modelle. Der Test der synthetischen Daten wurde mit der tf.Variable in Analogie zur Konfiguration von Modellen für ImageNet durchgeführt.
LeaderGPU®-Tests (ltbv20 2 Nvidia® Tesla® P 100)
Testumgebung:
- Instanztyp:ltbv20
- GPU:2x NVIDIA® Tesla® P100
- OS:CentOS 7
- CUDA / cuDNN:8.0 / 5.1
- TensorFlow GitHub Hash:b1e174e
- Benchmark GitHub Hash:9165a70
- Datum des Tests:Juni 2017
| Optionen | InceptionV3 | ResNet-50 | ResNet-152 | Alexnet | VGG16 |
|---|---|---|---|---|---|
| Stapelgröße auf GPU | 64 | 64 | 32 | 512 | 32 |
| Optimierung | sgd | sgd | sgd | sgd | sgd |
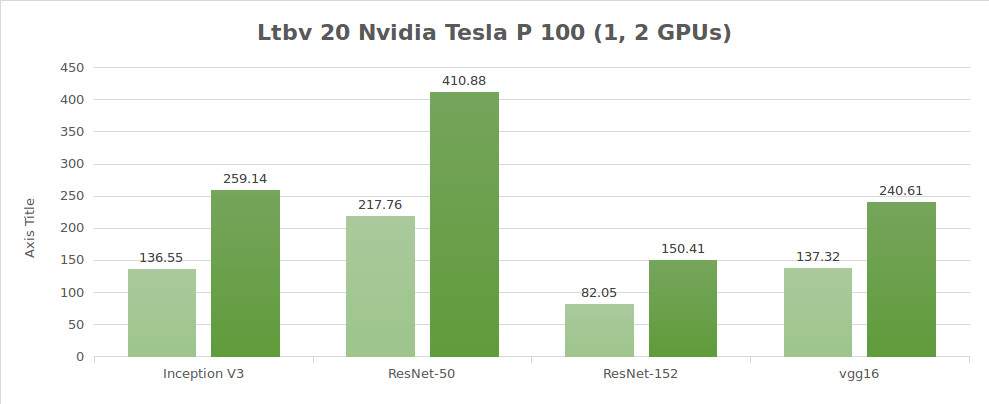
Test der synthetischen Daten (Bilder/Sekunde)
| GPUs | InceptionV3 | ResNet-50 | ResNet-152 | VGG16 | Alexnet |
|---|---|---|---|---|---|
| 1 | 136.55 | 217.76 | 82.05 | 137.32 | 2807.64 |
| 2 | 259.14 | 410.88 | 150.41 | 240.61 | 5117.86 |
Sonstige Ergebnisse
Test der synthetischen Daten (Bilder/Sekunde)
| Stapelgröße | alexnet | vgg11 | vgg16 | vgg19 | lenet | googlenet |
|---|---|---|---|---|---|---|
| 32 | 1516.70 | 373.45 | 240.61 | 203.73 | 14524.23 | 714.25 |
| 64 | 2480.30 | 472.15 | 274.67 | 230.73 | 28599.07 | 877.76 |
| 128 | 3486.68 | 540.51 | 288.80 | 243.55 | 44943.19 | 990.89 |
| 256 | 4440.35 | 464.69 | -* | -* | 63311.75 | 1075.38 |
| 512 | 5117.86 | -* | -* | -* | 80078.57 | 1104.74 |
| Stapelgröße | overfeat | inceptionv3 | inceptionv4 | resnet50 | resnet101 | resnet152 |
|---|---|---|---|---|---|---|
| 32 | 574.13 | 233.99 | 116.45 | 361.06 | 214.15 | 150.41 |
| 64 | 1052.63 | 259.14 | 125.09 | 410.88 | 245.36 | 170.79 |
| 128 | 1509.01 | 269.51 | -* | 439.41 | -* | -* |
| 256 | 2041.60 | -* | -* | -* | -* | -* |
| 512 | 2323.77 | -* | -* | -* | -* | -* |
* Der verfügbare GPU-Arbeitsspeicher erlaubt es nicht, Tests für diese Paketgröße (Stapelgröße) zu starten.
LeaderGPU®-Tests (GTX 1080)
Testumgebung:
- Instanztyp:ltbv17, 14, 16
- GPU:GTX 1080
- OS:CentOS 7
- CUDA / cuDNN:8.0 / 5.1
- TensorFlow GitHubb1e174e
- Benchmark GitHub Hash:9165a70
- Datum des Tests:Juni 2017
| Optionen | InceptionV3 | ResNet-50 | ResNet-152 | Alexnet | VGG16 |
|---|---|---|---|---|---|
| Stapelgröße auf GPU | 64 | 64 | 32 | 512 | 32 |
| Optimierung | sgd | sgd | sgd | sgd | sgd |
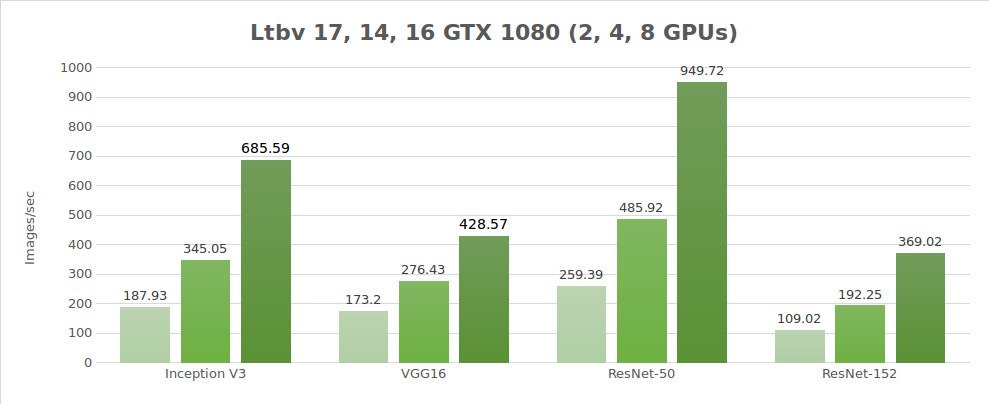
Test der synthetischen Daten (Bilder/Sekunde)
| GPUs | InceptionV3 | VGG16 | ResNet-50 | ResNet-152 | Alexnet |
|---|---|---|---|---|---|
| 2 | 187.93 | 173.2 | 259.39 | 109.02 | 3344.11 |
| 4 | 345.05 | 276.43 | 485.92 | 192.25 | 6221.67 |
| 8 | 685.59 | 428.57 | 949.72 | 369.02 | 9405.27 |
Sonstige Ergebnisse
Test der synthetischen Daten (Bilder/Sekunde)
2x GTX 1080
| Stapelgröße | alexnet | vgg11 | vgg16 | vgg19 | lenet | googlenet |
|---|---|---|---|---|---|---|
| 32 | 823.87 | 223.73 | 150.50 | 129.67 | 14440.58 | 608.46 |
| 64 | 1517.33 | 299.24 | 173.20 | 149.62 | 25817.36 | 676.81 |
| 128 | 2198.87 | 291.47 | -* | -* | 40910.02 | 717.52 |
| 256 | 2878.43 | -* | -* | -* | 53821.73 | 730.47 |
| 512 | 3344.11 | -* | -* | -* | 66096.43 | -* |
| Stapelgröße | overfeat | inceptionv3 | inceptionv4 | resnet50 | resnet101 | resnet152 |
|---|---|---|---|---|---|---|
| 32 | 284.06 | 180.62 | 91.63 | 245.55 | 154.15 | 109.02 |
| 64 | 568.15 | 187.93 | -* | 259.39 | -* | -* |
| 128 | 911.17 | -* | -* | -* | -* | -* |
| 256 | 1211.36 | -* | -* | -* | -* | -* |
| 512 | 1424.58 | -* | -* | -* | -* | -* |
* Der verfügbare GPU-Arbeitsspeicher erlaubt es nicht, Tests für diese Paketgröße (Stapelgröße) zu starten.
4x GTX 1080
| Stapelgröße | alexnet | vgg11 | vgg16 | vgg19 | lenet | googlenet |
|---|---|---|---|---|---|---|
| 32 | 1238.14 | 295.30 | 272.03 | 155.75 | 18389.01 | 1110.35 |
| 64 | 2375.18 | 354.55 | 276.43 | 169.51 | 37465.98 | 1235.77 |
| 128 | 3889.23 | 321.28 | -* | -* | 60612.34 | 1365.62 |
| 256 | 5056.10 | -* | -* | -* | 89908.56 | 1394.58 |
| 512 | 6221.67 | -* | -* | -* | 114433.39 | -* |
| Stapelgröße | overfeat | inceptionv3 | inceptionv4 | resnet50 | resnet101 | resnet152 |
|---|---|---|---|---|---|---|
| 32 | 450.85 | 328.23 | 166.82 | 447.25 | 276.27 | 192.25 |
| 64 | 885.37 | 345.05 | -* | 485.92 | -* | -* |
| 128 | 1576.74 | -* | -* | -* | -* | -* |
| 256 | 2126.47 | -* | -* | -* | -* | -* |
| 512 | 2447.81 | -* | -* | -* | -* | -* |
* Der verfügbare GPU-Arbeitsspeicher erlaubt es nicht, Tests für diese Paketgröße (Stapelgröße) zu starten.
8x GTX 1080
| Stapelgröße | alexnet | vgg11 | vgg16 | vgg19 | lenet | googlenet |
|---|---|---|---|---|---|---|
| 32 | 1347.98 | 381.49 | 347.37 | 333.71 | 27248.65 | 2023.19 |
| 64 | 2406.83 | 620.29 | 428.57 | -* | 51105.12 | 2352.15 |
| 128 | 4255.75 | -* | -* | -* | 93211.00 | 2644.26 |
| 256 | 6318.54 | -* | -* | -* | 145559.65 | 2610.21 |
| 512 | 9405.27 | -* | -* | -* | 206469.92 | -* |
| Stapelgröße | overfeat | inceptionv3 | inceptionv4 | resnet50 | resnet101 | resnet152 |
|---|---|---|---|---|---|---|
| 32 | 555.36 | 632.23 | 323.09 | 857.12 | 518.57 | 369.02 |
| 64 | 1042.12 | 685.59 | -* | 949.72 | -* | -* |
| 128 | 1735.24 | -* | -* | -* | -* | -* |
| 256 | 2575.93 | -* | -* | -* | -* | -* |
| 512 | 3815.25 | -* | -* | -* | -* | -* |
* Der verfügbare GPU-Arbeitsspeicher erlaubt es nicht, Tests für diese Paketgröße (Stapelgröße) zu starten.
LeaderGPU®-Tests (GTX 1080 Ti)
Testumgebung:
- Instanztyp:ltbv21, 18, 36
- GPU:GTX 1080TI
- OS:CentOS 7
- CUDA / cuDNN:8.0 / 5.1
- TensorFlow GitHubb1e174e
- Benchmark GitHub Hash:9165a70
- Datum des Tests:Juni 2017
| Optionen | InceptionV3 | ResNet-50 | ResNet-152 | Alexnet | VGG16 |
|---|---|---|---|---|---|
| Stapelgröße auf GPU | 64 | 64 | 32 | 512 | 32 |
| Optimierung | sgd | sgd | sgd | sgd | sgd |
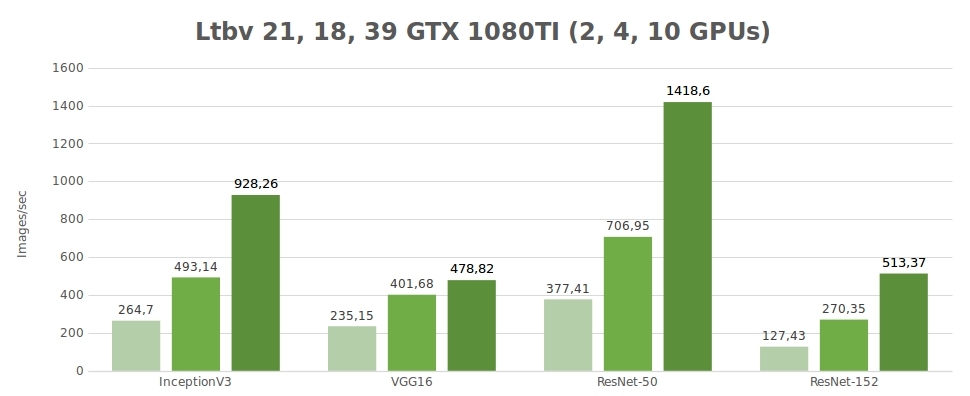
Test der synthetischen Daten (Bilder/Sekunde)
| GPUs | InceptionV3 | VGG16 | ResNet-50 | ResNet-152 | Alexnet |
|---|---|---|---|---|---|
| 2 | 264.7 | 235.15 | 377.41 | 127.43 | 4596.37 |
| 4 | 493.14 | 401.68 | 706.95 | 270.35 | 8513.54 |
| 10 | 928.26 | 478.82 | 1418.60 | 513.37 | - |
Sonstige Ergebnisse
Test der synthetischen Daten (Bilder/Sekunde)
2x GTX 1080 TI
| Stapelgröße | alexnet | vgg11 | vgg16 | vgg19 | lenet | googlenet |
|---|---|---|---|---|---|---|
| 32 | 880.18 | 287.25 | 190.05 | 169.67 | 13411.38 | 807.60 |
| 64 | 1743.20 | 385.95 | 235.15 | 198.28 | 28360.89 | 954.35 |
| 128 | 2808.68 | 457.54 | - | - | 44453.02 | 1042.77 |
| 256 | 3777.74 | - | - | - | 67451.51 | 1070.28 |
| 512 | 4596.37 | - | - | - | 87898.53 | - |
| Stapelgröße | overfeat | inceptionv3 | inceptionv4 | resnet50 | resnet101 | resnet152 |
|---|---|---|---|---|---|---|
| 32 | 304.50 | 250.37 | 125.81 | 351.21 | 218.02 | 127.43 |
| 64 | 607.91 | 264.70 | - | 377.41 | 236.24 | - |
| 128 | 1162.21 | - | - | 381.62 | - | - |
| 256 | 1617.89 | - | - | - | - | - |
| 512 | 1992.50 | - | - | - | - | - |
4x GTX 1080 TI
| Stapelgröße | alexnet | vgg11 | vgg16 | vgg19 | lenet | googlenet |
|---|---|---|---|---|---|---|
| 32 | 1264.01 | 378.39 | 331.08 | 208.39 | 19239.51 | 1487.66 |
| 64 | 2502.01 | 481.49 | 401.68 | 236.07 | 38818.10 | 1755.63 |
| 128 | 4539.97 | 541.39 | - | - | 71457.41 | 1943.93 |
| 256 | 6787.68 | - | - | - | 111721.23 | 1992.45 |
| 512 | 8513.54 | - | - | - | 152549.70 | -* |
| Stapelgröße | overfeat | inceptionv3 | inceptionv4 | resnet50 | resnet101 | resnet152 |
|---|---|---|---|---|---|---|
| 32 | 475.69 | 451.16 | 228.76 | 648.11 | 383.04 | 270.35 |
| 64 | 942.19 | 493.14 | - | 706.95 | 422.93 | - |
| 128 | 1706.03 | - | - | 722.16 | - | - |
| 256 | 2907.18 | - | - | - | - | - |
| 512 | 3478.50 | - | - | - | - | - |
10x GTX 1080 TI
| Batch size | alexnet | vgg11 | vgg16 | vgg19 | lenet | googlenet |
|---|---|---|---|---|---|---|
| 32 | 865.89 | 368.50 | 309.07 | 289.88 | 18065.32 | 2200.48 |
| 64 | 1719.84 | 667.04 | 478.82 | 465.45 | 36486.24 | 3333.87 |
| 128 | 3344.45 | 868.66 | - | - | 70077.18 | 3771.19 |
| 256 | 6159.03 | - | - | - | 138600.70 | 4335.86 |
| 512 | - | - | - | 237511.15 | - |
| Batch size | overfeat | inceptionv3 | inceptionv4 | resnet50 | resnet101 | resnet152 |
|---|---|---|---|---|---|---|
| 32 | 346.22 | 809.19 | 459.10 | 1116.42 | 760.83 | 513.37 |
| 64 | 676.99 | 928.26 | - | 1418.60 | 937.95 | - |
| 128 | 1322.01 | - | - | 1504.64 | - | - |
| 256 | 2387.97 | - | - | - | - | - |
| 512 | - | - | - | - | - | - |
AWS EC2-Tests (NVIDIA® Tesla® K80)
Testumgebung:
- Instanztyp:p2.8xlarge
- GPU:8x NVIDIA® Tesla® K80
- OS:Ubuntu 16.04 LTS
- CUDA / cuDNN:8.0 / 5.1
- TensorFlow GitHubb1e174e
- Benchmark GitHub Hash:9165a70
- Datum des Tests:Mai 2017
| Optionen | InceptionV3 | ResNet-50 | ResNet-152 | Alexnet | VGG16 |
|---|---|---|---|---|---|
| Stapelgröße auf GPU | 64 | 64 | 32 | 512 | 32 |
| Optimierung | sgd | sgd | sgd | sgd | sgd |
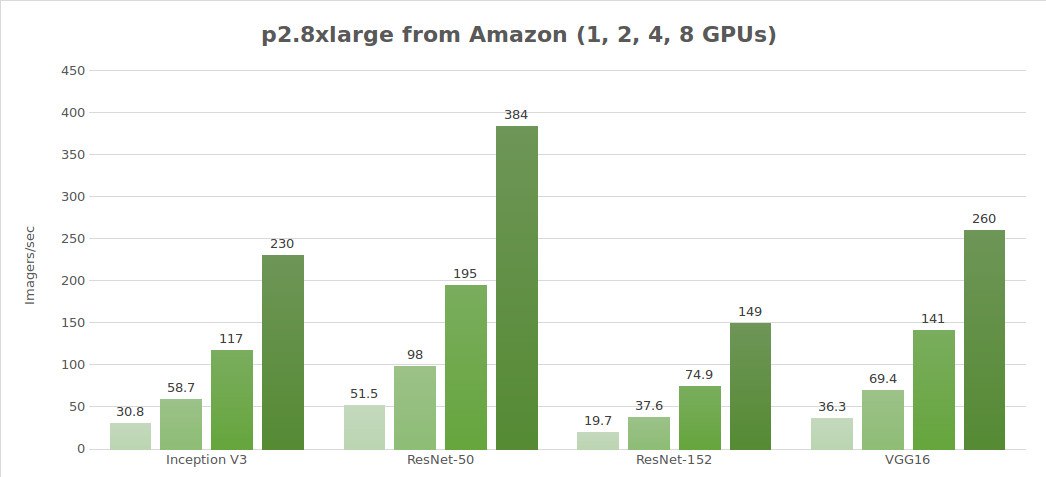
Test der synthetischen Daten (Bilder/Sekunde)
| GPUs | InceptionV3 | ResNet-50 | ResNet-152 | Alexnet | VGG16 |
|---|---|---|---|---|---|
| 1 | 30.8 | 51.5 | 19.7 | 684 | 36.3 |
| 2 | 58.7 | 98.0 | 37.6 | 1244 | 69.4 |
| 4 | 117 | 195 | 74.9 | 2479 | 141 |
| 8 | 230 | 384 | 149 | 4853 | 260 |
Sonstige Ergebnisse (Bilder/Sekunde)
| GPUs | InceptionV3 (batch size 32) | ResNet-50 (batch size 32) |
|---|---|---|
| 1 | 29.9 | 49.0 |
| 2 | 57.5 | 94.1 |
| 4 | 114 | 184 |
| 8 | 216 | 355 |
Die Testergebnisse stammen von https://www.tensorflow.org/lite/performance/measurement#details_for_amazon_ec2_nvidia_tesla_k80
Google Compute Engine-Tests (NVIDIA® Tesla® K80)
Testumgebung:
- Instanztyp:n1-standard-32-k80x8
- GPU:8x NVIDIA® Tesla® K80
- OS:Ubuntu 16.04 LTS
- CUDA / cuDNN:8.0 / 5.1
- TensorFlow GitHubb1e174e
- Benchmark GitHub Hash:9165a70
- Datum des Tests:Mai 2017
| Optionen | InceptionV3 | ResNet-50 | ResNet-152 | Alexnet | VGG16 |
|---|---|---|---|---|---|
| Stapelgröße auf GPU | 64 | 64 | 32 | 512 | 32 |
| Optimierung | sgd | sgd | sgd | sgd | sgd |
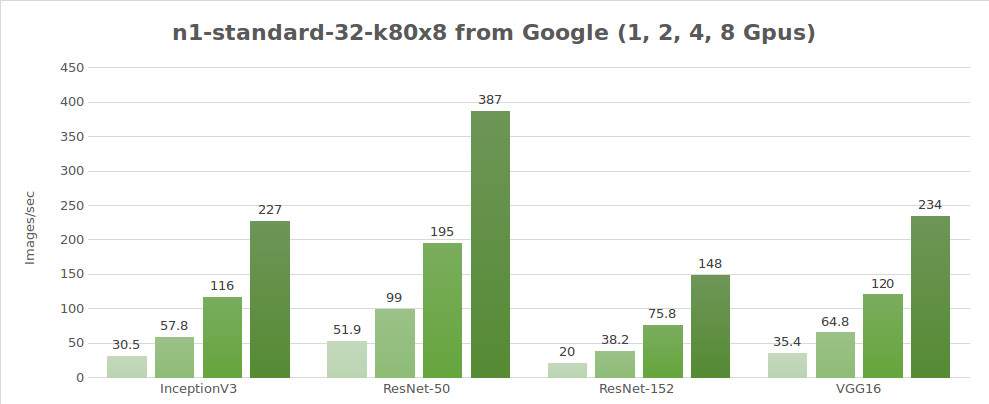
Test der synthetischen Daten (Bilder/Sekunde)
| GPUs | InceptionV3 | ResNet-50 | ResNet-152 | Alexnet | VGG16 |
|---|---|---|---|---|---|
| 1 | 30.5 | 51.9 | 20.0 | 656 | 35.4 |
| 2 | 57.8 | 99.0 | 38.2 | 1209 | 64.8 |
| 4 | 116 | 195 | 75.8 | 2328 | 120 |
| 8 | 227 | 387 | 148 | 4640 | 234 |
Sonstige Ergebnisse (Bilder/Sekunde)
| GPUs | InceptionV3 (batch size 32) | ResNet-50 (batch size 32) |
|---|---|---|
| 1 | 29.3 | 49.5 |
| 2 | 55.0 | 95.4 |
| 4 | 109 | 183 |
| 8 | 216 | 362 |
Die Testergebnisse stammen von https://www.tensorflow.org/lite/performance/measurement#details_for_google_compute_engine_nvidia_tesla_k80
Lassen Sie uns nun die Kosten für die Bildverarbeitung anschauen.
In der nachstehenden Tabelle werden die Kosten und die Verarbeitungszeit für 500.000 Bilder mit den Modellen Inception V3, ResNet-60 und ResNet-152 berechnet, um das beste Angebot zu ermitteln. Wie aus der Tabelle ersichtlich ist, ist LeaderGPU® das günstigste Marktangebot unter den anderen untersuchten Anbietern.
| Modell | GPU | Plattform | Anzahl der Bilder | Zeit | Preis (pro Minute) | Gesamtkosten |
|---|---|---|---|---|---|---|
| Inception V3 | 8x K80 | Google cloud | 500000 | 36m 43sec | €0.0825* | €3.02* |
| Inception V3 | 8x K80 | AWS | 500000 | 36m 14sec | €0.107* | €3.87* |
| Inception V3 | 8x 1080 | LeaderGPU | 500000 | 12m 9sec | €0.11 | €1.34 |
| ResNet-50 | 8x K80 | Google cloud | 500000 | 21m 32sec | €0.0825* | €1.77* |
| ResNet-50 | 8x K80 | AWS | 500000 | 21m 42 sec | €0.107* | €2.32* |
| ResNet-50 | 8x 1080 | LeaderGPU | 500000 | 8m 46sec | €0.11 | €0.96 |
| ResNet-152 | 8x K80 | Google cloud | 500000 | 56m 18sec | €0.0825* | €4.64* |
| ResNet-152 | 8x K80 | AWS | 500000 | 55m 55sec | €0.107* | €5.98* |
| ResNet-152 | 8x 1080 | LeaderGPU | 500000 | 22m 35sec | €0.11 | €2.48 |
* Der Google Cloud-Dienst wird nicht pro Minute angeboten. Die Kosten pro Minute werden auf der Grundlage des Stundenpreises (5,645 $) berechnet.