





Ihr eigener LLaMa 2 unter Linux

Schritt 1. Betriebssystem vorbereiten
Cache und Pakete aktualisieren
Bevor Sie mit der Einrichtung von LLaMa 2 beginnen, sollten Sie den Paket-Cache aktualisieren und Ihr Betriebssystem aufrüsten. Bitte beachten Sie, dass wir für diese Anleitung Ubuntu 22.04 LTS als Betriebssystem verwenden:
sudo apt update && sudo apt -y upgradeAußerdem müssen wir Python Installer Packages (PIP) hinzufügen, falls es nicht bereits im System vorhanden ist:
sudo apt install python3-pipNvidia-Treiber installieren
Sie können das automatische Dienstprogramm verwenden, das in Ubuntu-Distributionen standardmäßig enthalten ist:
sudo ubuntu-drivers autoinstallAlternativ können Sie die Nvidia-Treiber auch manuell mit Hilfe unserer Schritt-für-Schritt-Anleitung installieren. Vergessen Sie nicht, den Server neu zu starten:
sudo shutdown -r nowSchritt 2. Modelle von MetaAI abrufen
Offizielle Anfrage
Öffnen Sie die folgende Adresse in Ihrem Browser: https://ai.meta.com/resources/models-and-libraries/llama-downloads/
Füllen Sie alle erforderlichen Felder aus, lesen Sie die Benutzervereinbarung und klicken Sie auf die Schaltfläche Agree and Continue. Nach ein paar Minuten (Stunden, Tagen) erhalten Sie eine spezielle Download-URL, die Ihnen die Erlaubnis erteilt, Modelle für einen Zeitraum von 24 Stunden herunterzuladen.
Klonen Sie das Repository
Bitte überprüfen Sie vor dem Download den verfügbaren Speicherplatz:
df -hFilesystem Size Used Avail Use% Mounted on tmpfs 38G 3.3M 38G 1% /run /dev/sda2 99G 24G 70G 26% / tmpfs 189G 0 189G 0% /dev/shm tmpfs 5.0M 0 5.0M 0% /run/lock /dev/nvme0n1 1.8T 26G 1.7T 2% /mnt/fastdisk tmpfs 38G 8.0K 38G 1% /run/user/1000
Wenn Sie nicht gemountete lokale Festplatten haben, befolgen Sie bitte die Anweisungen unter Festplattenpartitionierung in Linux. Dies ist wichtig, da die heruntergeladenen Modelle sehr groß sein können und Sie deren Speicherort im Voraus planen müssen. In diesem Beispiel haben wir eine lokale SSD im Verzeichnis /mnt/fastdisk eingehängt. Öffnen wir es:
cd /mnt/fastdiskErstellen Sie eine Kopie des ursprünglichen LLaMa-Repositorys:
git clone https://github.com/facebookresearch/llamaWenn Sie auf einen Berechtigungsfehler stoßen, erteilen Sie einfach dem Benutzerergpu die Berechtigungen:
sudo chown -R usergpu:usergpu /mnt/fastdisk/Herunterladen per Skript
Öffnen Sie das heruntergeladene Verzeichnis:
cd llamaFühren Sie das Skript aus:
./download.shGeben Sie die von MetaAI bereitgestellte URL ein und wählen Sie alle erforderlichen Modelle aus. Wir empfehlen, alle verfügbaren Modelle herunterzuladen, damit Sie nicht erneut um Erlaubnis bitten müssen. Wenn Sie jedoch ein bestimmtes Modell benötigen, laden Sie nur dieses herunter.
Schnelltest über Beispiel-App
Zu Beginn können wir prüfen, ob Komponenten fehlen. Wenn Bibliotheken oder Anwendungen fehlen, werden sie vom Paketmanager automatisch installiert:
pip install -e .Der nächste Schritt besteht darin, neue Binärdateien zu PATH hinzuzufügen:
export PATH=/home/usergpu/.local/bin:$PATHFühren Sie das Demo-Beispiel aus:
torchrun --nproc_per_node 1 /mnt/fastdisk/llama/example_chat_completion.py --ckpt_dir /mnt/fastdisk/llama-2-7b-chat/ --tokenizer_path /mnt/fastdisk/llama/tokenizer.model --max_seq_len 512 --max_batch_size 6Die Anwendung erstellt einen Rechenprozess auf der ersten GPU und simuliert einen einfachen Dialog mit typischen Anfragen, wobei die Antworten mit LLaMa 2 generiert werden.
Schritt 3. llama.cpp holen
LLaMa C++ ist ein Projekt des bulgarischen Physikers und Softwareentwicklers Georgi Gerganov. Es enthält viele nützliche Hilfsprogramme, die die Arbeit mit diesem neuronalen Netzwerkmodell erleichtern. Alle Teile von llama.cpp sind Open-Source-Software und werden unter der MIT-Lizenz vertrieben.
Klonen Sie das Repository
Öffnen Sie das Arbeitsverzeichnis auf der SSD:
cd /mnt/fastdiskKlonen Sie das Repository des Projekts:
git clone https://github.com/ggerganov/llama.cpp.gitAnwendungen kompilieren
Öffnen Sie das geklonte Verzeichnis:
cd llama.cppStarten Sie den Kompilierungsprozess mit dem folgenden Befehl:
makeSchritt 4. Holen Sie text-generation-webui
Klonen Sie das Repository
Öffnen Sie das Arbeitsverzeichnis auf der SSD:
cd /mnt/fastdiskKlonen Sie das Repository des Projekts:
git clone https://github.com/oobabooga/text-generation-webui.gitAnforderungen installieren
Öffnen Sie das heruntergeladene Verzeichnis:
cd text-generation-webuiÜberprüfen und installieren Sie alle fehlenden Komponenten:
pip install -r requirements.txtSchritt 5. PTH in GGUF umwandeln
Gängige Formate
PTH (Python TorcH) - Ein konsolidiertes Format. Im Wesentlichen handelt es sich um ein Standard-ZIP-Archiv mit einem serialisierten PyTorch-Zustandswörterbuch. Für dieses Format gibt es jedoch schnellere Alternativen wie GGML und GGUF.
GGML (Georgi Gerganov’s Machine Learning) - Dies ist ein Dateiformat, das von Georgi Gerganov, dem Autor von llama.cpp, entwickelt wurde. Es basiert auf einer gleichnamigen, in C++ geschriebenen Bibliothek, die die Leistung von großen Sprachmodellen erheblich gesteigert hat. Es wurde nun durch das moderne GGUF-Format ersetzt.
GGUF (Georgi Gerganov’s Unified Format) - Ein weit verbreitetes Dateiformat für LLMs, das von verschiedenen Anwendungen unterstützt wird. Es bietet verbesserte Flexibilität, Skalierbarkeit und Kompatibilität für die meisten Anwendungsfälle.
llama.cpp convert.py Skript
Bearbeiten Sie die Parameter des Modells vor der Konvertierung:
nano /mnt/fastdisk/llama-2-7b-chat/params.jsonKorrigieren Sie "vocab_size": -1 auf "vocab_size": 32000. Speichern Sie die Datei und beenden Sie sie. Öffnen Sie dann das Verzeichnis llama.cpp:
cd /mnt/fastdisk/llama.cppFühren Sie das Skript aus, das das Modell in das GGUF-Format konvertiert:
python3 convert.py /mnt/fastdisk/llama-2-7b-chat/ --vocab-dir /mnt/fastdisk/llamaWenn alle vorherigen Schritte korrekt ausgeführt wurden, erhalten Sie eine Meldung wie diese:
Wrote /mnt/fastdisk/llama-2-7b-chat/ggml-model-f16.gguf
Schritt 6. WebUI
So starten Sie WebUI
Öffnen Sie das Verzeichnis:
cd /mnt/fastdisk/text-generation-webui/Führen Sie das Startskript mit einigen nützlichen Parametern aus:
- --model-dir gibt den korrekten Pfad zu den Modellen an
- --share erstellt einen temporären öffentlichen Link (wenn Sie keinen Port über SSH weiterleiten wollen)
- --gradio-auth fügt eine Autorisierung mit Login und Passwort hinzu (ersetzen Sie user:password durch Ihr eigenes)
./start_linux.sh --model-dir /mnt/fastdisk/llama-2-7b-chat/ --share --gradio-auth user:passwordNach erfolgreichem Start erhalten Sie einen lokalen und einen temporären Freigabelink für den Zugriff:
Running on local URL: http://127.0.0.1:7860 Running on public URL: https://e9a61c21593a7b251f.gradio.live
Dieser Freigabelink läuft in 72 Stunden ab.
Laden Sie das Modell
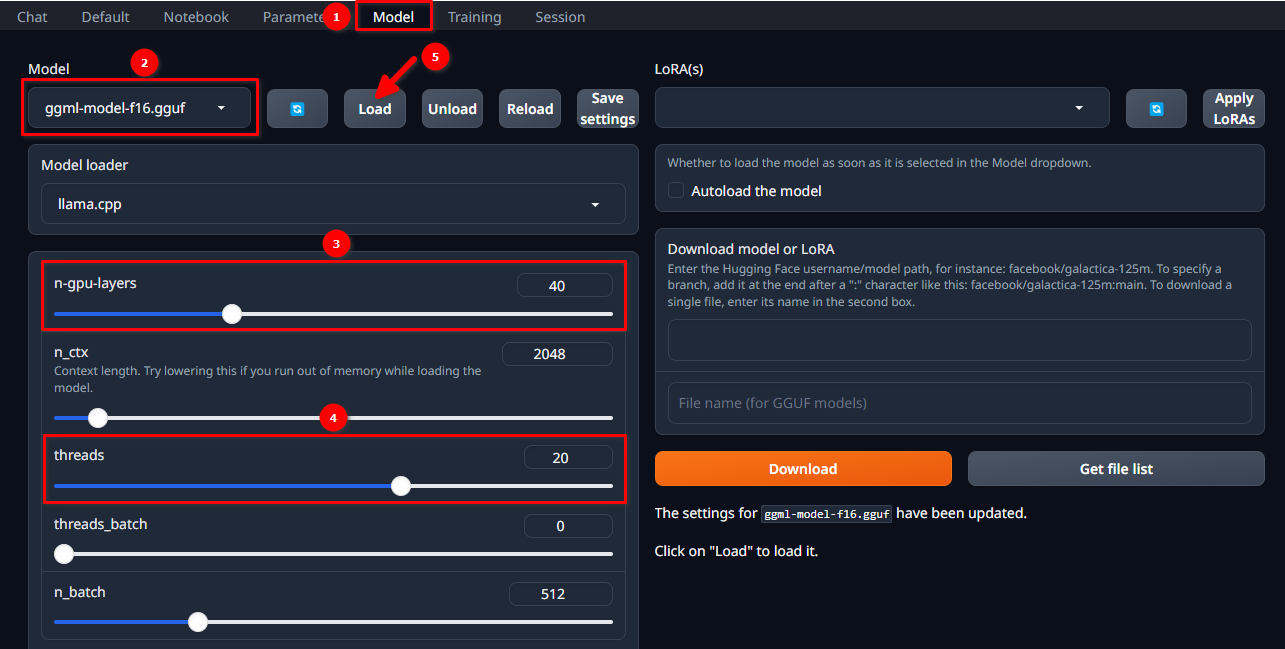
Autorisieren Sie sich in der WebUI mit dem gewählten Benutzernamen und Passwort und folgen Sie diesen 5 einfachen Schritten:
- Navigieren Sie zur Registerkarte Model.
- Wählen Sie ggml-model-f16.gguf aus dem Dropdown-Menü.
- Wählen Sie, wie viele Schichten Sie auf dem Grafikprozessor berechnen möchten (n-gpu-layers).
- Wählen Sie, wie viele Threads Sie starten möchten (threads).
- Klicken Sie auf die Schaltfläche Load.
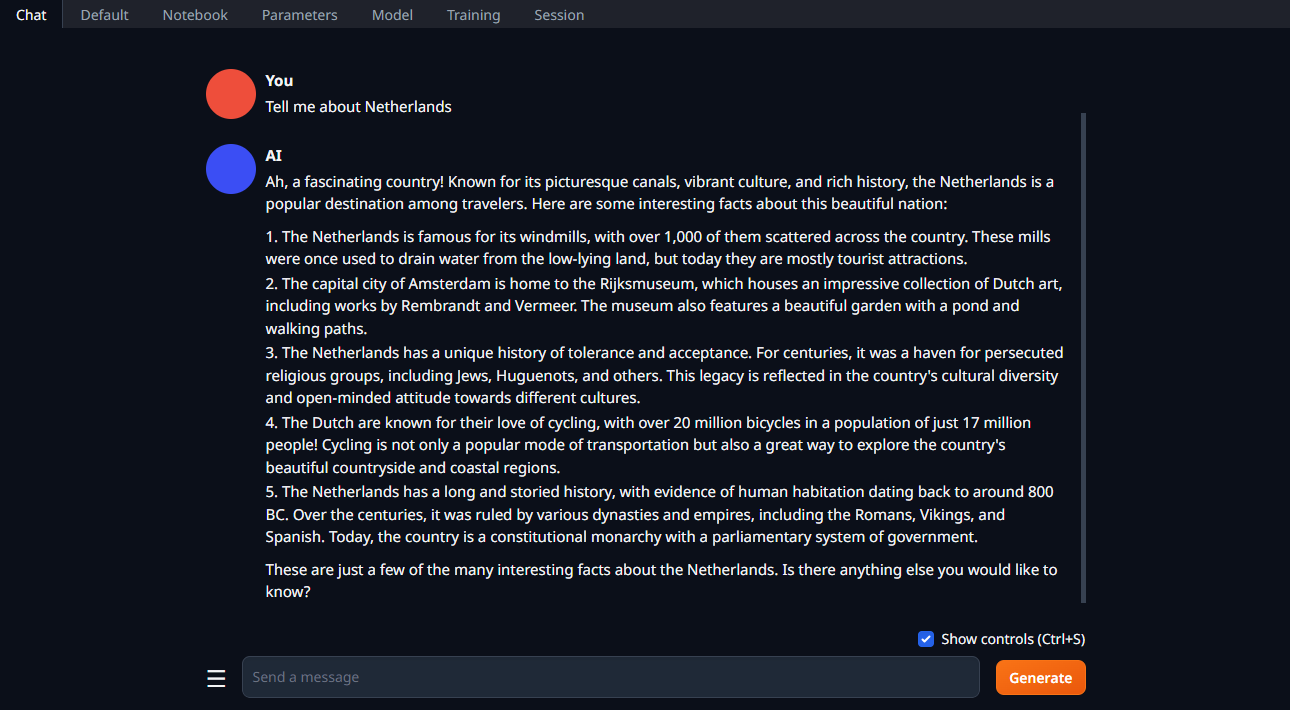
Starten Sie den Dialog
Ändern Sie die Registerkarte auf Chat, geben Sie Ihre Eingabeaufforderung ein und klicken Sie auf Generate:
Siehe auch:
Aktualisiert: 04.01.2026
Veröffentlicht: 20.01.2025




