





Llama 3 mit Hugging Face

Am 18. April 2024 wurde das neueste große Sprachmodell von MetaAI, Llama 3, veröffentlicht. Zwei Versionen wurden den Benutzern vorgestellt: 8B und 70B. Die erste Version enthält mehr als 15K Token und wurde mit Daten trainiert, die bis März 2023 gültig waren. Die zweite, größere Version wurde mit Daten trainiert, die bis Dezember 2023 gültig sind.
Schritt 1. Vorbereiten des Betriebssystems
Cache und Pakete aktualisieren
Bevor Sie mit der Einrichtung von LLaMa 3 beginnen, sollten Sie den Paket-Cache aktualisieren und Ihr Betriebssystem aufrüsten. Bitte beachten Sie, dass wir für diese Anleitung Ubuntu 22.04 LTS als Betriebssystem verwenden:
sudo apt update && sudo apt -y upgradeAußerdem müssen wir Python Installer Packages (PIP) hinzufügen, falls es nicht bereits im System vorhanden ist:
sudo apt install python3-pipNvidia-Treiber installieren
Sie können das automatische Dienstprogramm verwenden, das in Ubuntu-Distributionen standardmäßig enthalten ist:
sudo ubuntu-drivers autoinstallAlternativ können Sie die Nvidia-Treiber auch manuell installieren. Vergessen Sie nicht, den Server neu zu starten:
sudo shutdown -r nowSchritt 2. Holen Sie sich das Modell
Melden Sie sich bei Hugging Face mit Ihrem Benutzernamen und Passwort an. Gehen Sie auf die Seite, die der gewünschten LLM-Version entspricht: Meta-Llama-3-8B oder Meta-Llama-3-70B. Zum Zeitpunkt der Veröffentlichung dieses Artikels wird der Zugang zum Modell auf individueller Basis gewährt. Füllen Sie ein kurzes Formular aus und klicken Sie auf die Schaltfläche Submit:
Zugang bei HF beantragen
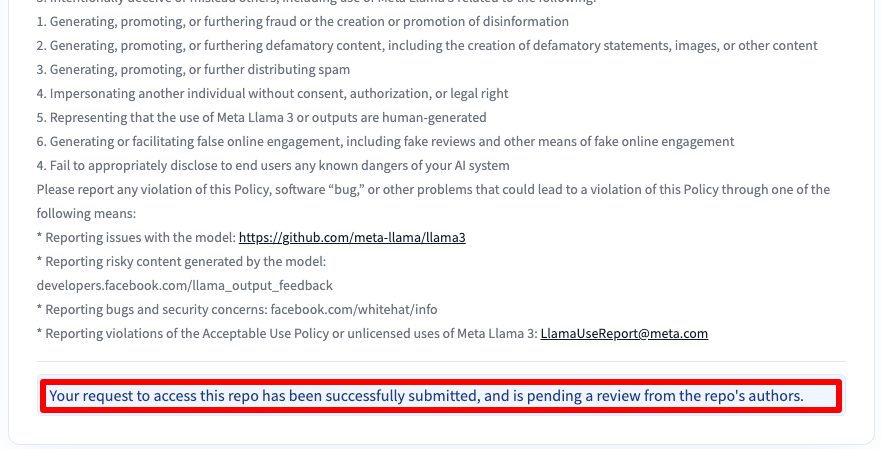
Sie erhalten dann eine Nachricht, dass Ihr Antrag eingereicht wurde:
Sie erhalten nach 30-40 Minuten Zugang und werden darüber per E-Mail benachrichtigt.
SSH-Schlüssel zu HF hinzufügen
Erzeugen und fügen Sie einen SSH-Schlüssel hinzu, den Sie in Hugging Face verwenden können:
cd ~/.ssh && ssh-keygenWenn das Schlüsselpaar generiert ist, können Sie den öffentlichen Schlüssel im Terminalemulator anzeigen:
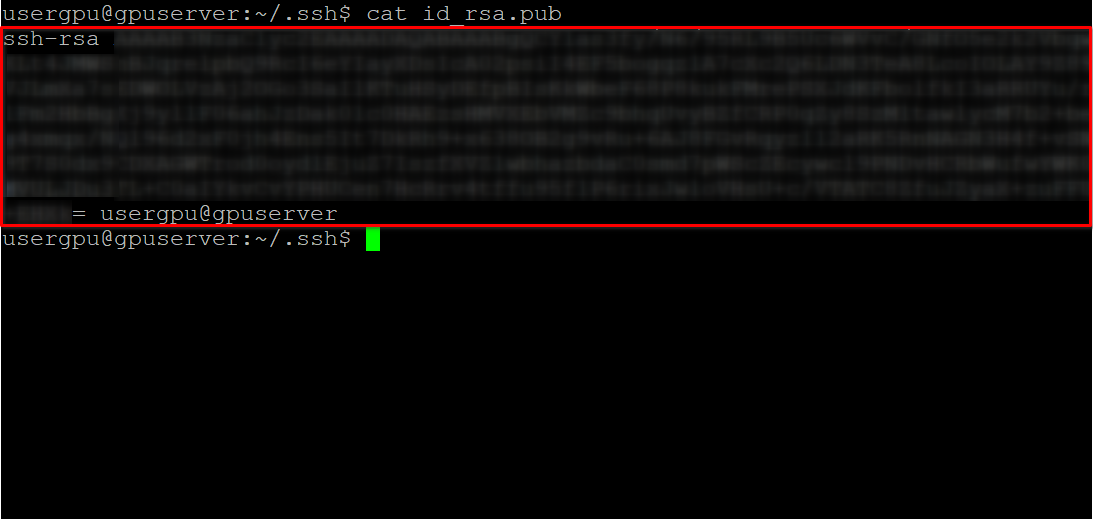
cat id_rsa.pubKopieren Sie alle Informationen, beginnend mit ssh-rsa und endend mit usergpu@gpuserver, wie im folgenden Screenshot gezeigt:
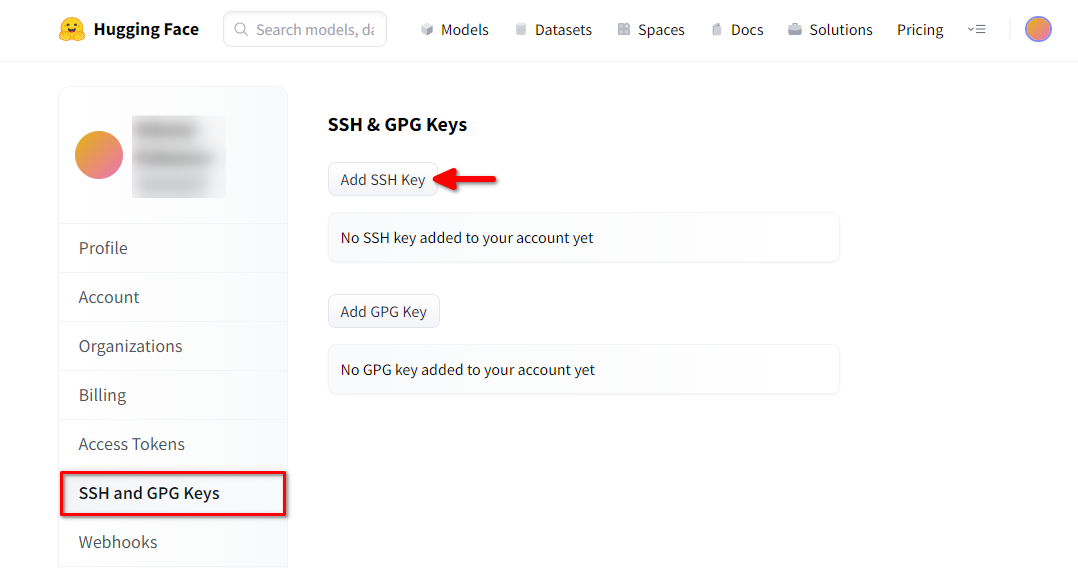
Öffnen Sie die Profileinstellungen von Hugging Face. Wählen Sie dann SSH and GPG Keys und klicken Sie auf die Schaltfläche SSH-Schlüssel hinzufügen:
Füllen Sie Key name aus und fügen Sie den kopierten SSH Public key aus dem Terminal ein. Speichern Sie den Schlüssel durch Drücken von Add key:
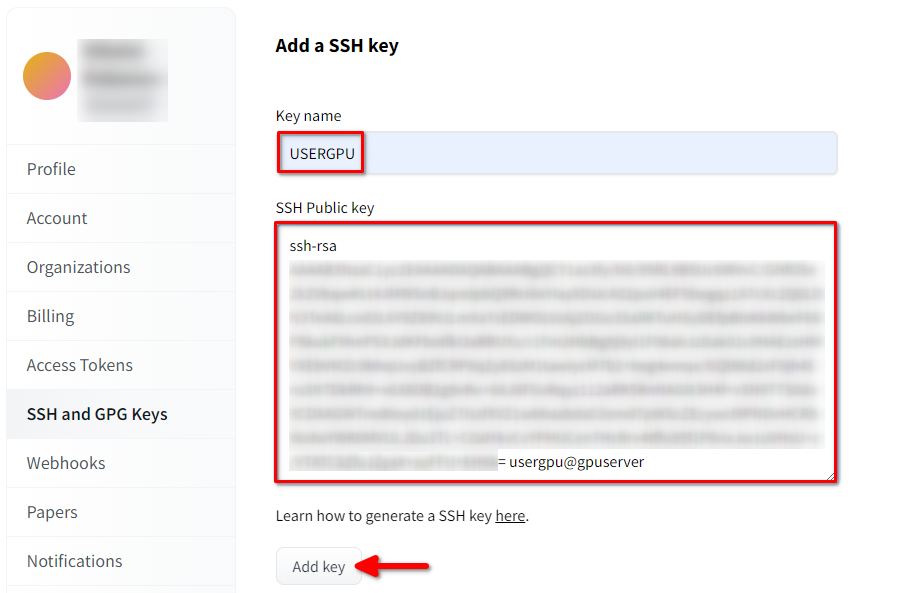
Nun ist Ihr HF-Konto mit dem öffentlichen SSH-Schlüssel verknüpft. Der zweite Teil (privater Schlüssel) ist auf dem Server gespeichert. Der nächste Schritt ist die Installation einer speziellen Git LFS-Erweiterung (Large File Storage), die für das Herunterladen großer Dateien wie z. B. Modelle neuronaler Netze verwendet wird. Öffnen Sie Ihr Home-Verzeichnis:
cd ~/Laden Sie das Shell-Skript herunter und führen Sie es aus. Dieses Skript installiert ein neues Drittanbieter-Repository mit git-lfs:
curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bashNun können Sie es mit dem Standard-Paketmanager installieren:
sudo apt-get install git-lfsLassen Sie uns git so konfigurieren, dass es unseren HF-Nickname verwendet:
git config --global user.name "John"Und mit dem HF-E-Mail-Konto verknüpft:
git config --global user.email "john.doe@example.com"Das Modell herunterladen
Öffnen Sie das Zielverzeichnis:
cd /mnt/fastdiskUnd beginnen Sie mit dem Download des Repositorys. Für dieses Beispiel haben wir die Version 8B gewählt:
git clone git@hf.co:meta-llama/Meta-Llama-3-8BDieser Vorgang dauert bis zu 5 Minuten und kann durch Ausführen des folgenden Befehls in einer anderen SSH-Konsole überwacht werden:
watch -n 0.5 df -hHier sehen Sie, wie der freie Speicherplatz auf dem gemounteten Datenträger verringert wird, um sicherzustellen, dass der Download fortschreitet und die Daten gespeichert werden. Der Status wird jede halbe Sekunde aktualisiert. Um die Anzeige manuell zu beenden, drücken Sie die Tastenkombination Strg + C.
Alternativ können Sie auch btop installieren und den Prozess mit diesem Dienstprogramm überwachen:
sudo apt -y install btop && btop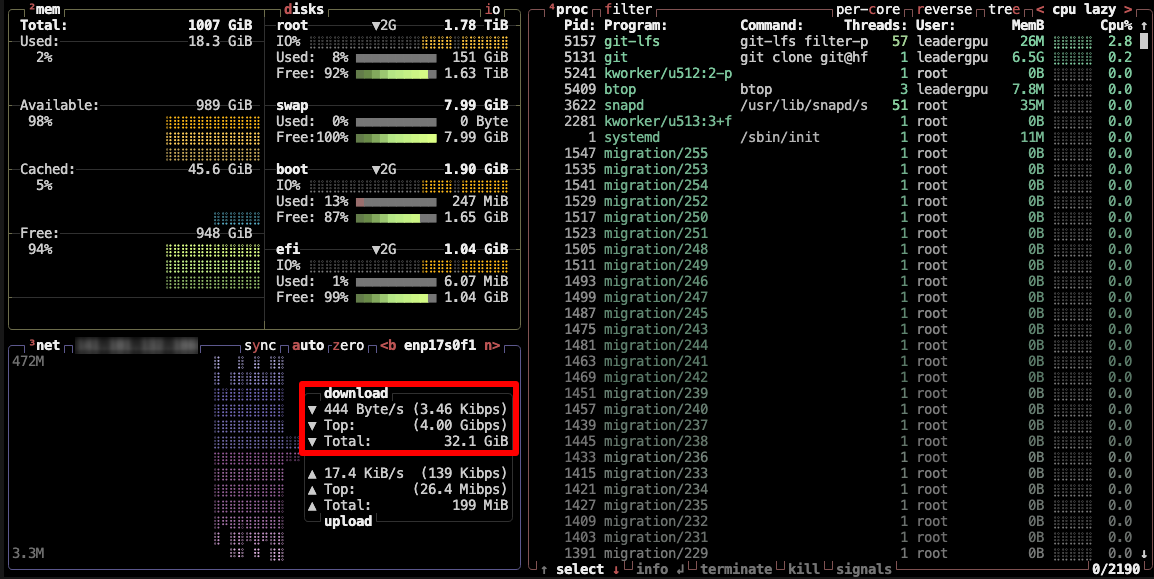
Um das Dienstprogramm btop zu beenden, drücken Sie die Taste Esc und wählen Sie Quit.
Schritt 3. Ausführen des Modells
Öffnen Sie das Verzeichnis:
cd /mnt/fastdiskLaden Sie das Llama 3 Repository herunter:
git clone https://github.com/meta-llama/llama3Wechseln Sie das Verzeichnis:
cd llama3Führen Sie das Beispiel aus:
torchrun --nproc_per_node 1 example_text_completion.py \
--ckpt_dir /mnt/fastdisk/Meta-Llama-3-8B/original \
--tokenizer_path /mnt/fastdisk/Meta-Llama-3-8B/original/tokenizer.model \
--max_seq_len 128 \
--max_batch_size 4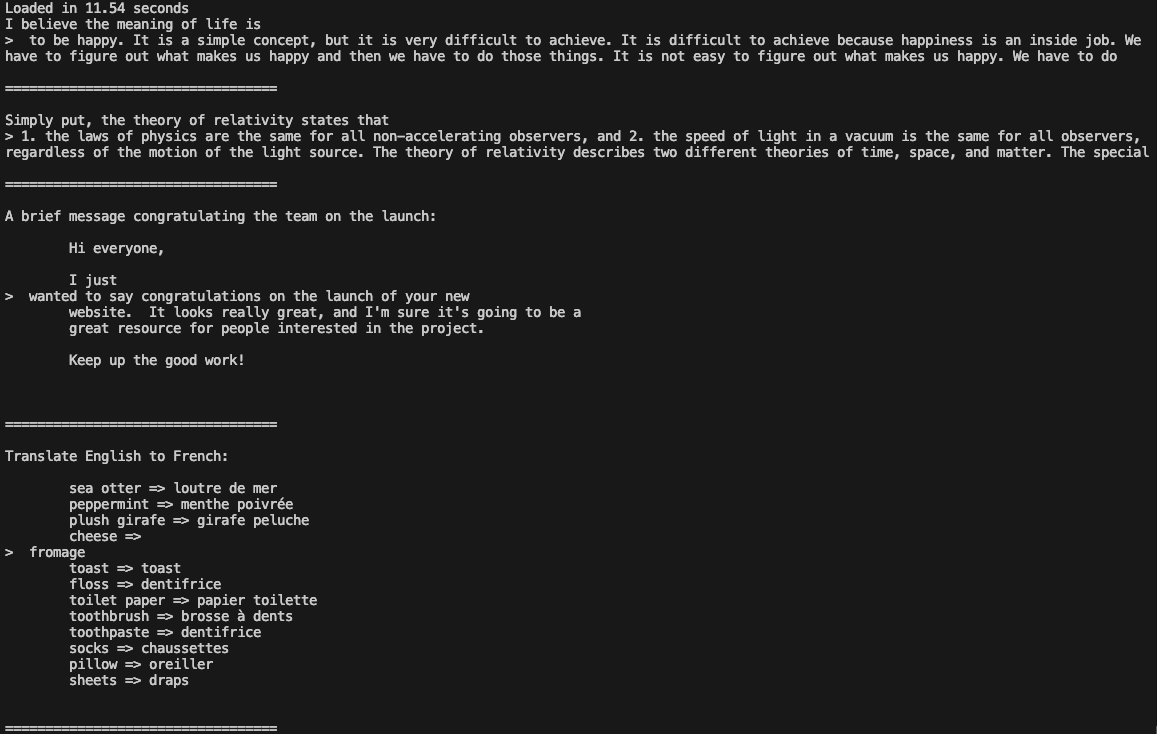
Jetzt können Sie Llama 3 in Ihren Anwendungen verwenden.
Siehe auch:
Aktualisiert: 04.01.2026
Veröffentlicht: 20.01.2025




