





Qwen 2 gegen Llama 3

Große Sprachmodelle (Large Language Models, LLMs) haben unser Leben erheblich beeinflusst. Trotz des Verständnisses ihrer internen Struktur bleiben diese Modelle ein Brennpunkt für Wissenschaftler, die sie oft mit einer "Black Box" vergleichen. Das Endergebnis hängt nicht nur vom Design des LLM ab, sondern auch von seinem Training und den für das Training verwendeten Daten.
Während Wissenschaftler nach Forschungsmöglichkeiten suchen, sind die Endnutzer vor allem an zwei Dingen interessiert: Geschwindigkeit und Qualität. Diese Kriterien spielen im Auswahlprozess eine entscheidende Rolle. Um zwei LLMs genau vergleichen zu können, müssen viele scheinbar unzusammenhängende Faktoren standardisiert werden.
Den größten Einfluss haben die zur Störung verwendeten Geräte und die Softwareumgebung, einschließlich des Betriebssystems, der Treiberversionen und der Softwarepakete. Es ist wichtig, eine LLM-Version auszuwählen, die auf verschiedenen Geräten funktioniert, und eine Geschwindigkeitsmetrik zu wählen, die leicht zu verstehen ist.
Wir haben uns für "Token pro Sekunde" (Token/s) als diese Metrik entschieden. Es ist wichtig zu wissen, dass ein Token ≠ ein Wort ist. Das LLM zerlegt Wörter in einfachere, für eine bestimmte Sprache typische Komponenten, die als Token bezeichnet werden.
Die statistische Vorhersagbarkeit des nächsten Zeichens variiert von Sprache zu Sprache, so dass die Tokenisierung unterschiedlich ausfällt. Im Englischen zum Beispiel werden aus 75 Wörtern etwa 100 Token abgeleitet. In Sprachen, die das kyrillische Alphabet verwenden, kann die Anzahl der Token pro Wort höher sein. So könnten 75 Wörter in einer kyrillischen Sprache wie Russisch 120-150 Token entsprechen.
Sie können dies mit dem Tokenizer-Tool von OpenAI überprüfen. Es zeigt, in wie viele Token ein Textfragment zerlegt wird, so dass "Token pro Sekunde" ein guter Indikator für die Geschwindigkeit und Leistung eines LLM bei der Verarbeitung natürlicher Sprache ist.
Jeder Test wurde auf dem Betriebssystem Ubuntu 22.04 LTS mit den Nvidia-Treibern Version 535.183.01 und dem NVIDIA® CUDA® 12.5 Toolkit durchgeführt. Es wurden Fragen formuliert, um die Qualität und Geschwindigkeit des LLM zu bewerten. Die Verarbeitungsgeschwindigkeit jeder Antwort wurde aufgezeichnet und wird zum Durchschnittswert für jede getestete Konfiguration beitragen.
Wir begannen mit dem Test verschiedener GPUs, von den neuesten Modellen bis hin zu den älteren. Eine entscheidende Bedingung für den Test war, dass wir die Leistung nur eines Grafikprozessors gemessen haben, auch wenn mehrere in der Serverkonfiguration vorhanden waren. Dies liegt daran, dass die Leistung einer Konfiguration mit mehreren Grafikprozessoren von zusätzlichen Faktoren wie dem Vorhandensein eines Hochgeschwindigkeits-Interconnects zwischen ihnen (NVLink) abhängt.
Neben der Geschwindigkeit haben wir auch versucht, die Qualität der Antworten auf einer 5-Punkte-Skala zu bewerten, wobei 5 das beste Ergebnis darstellt. Diese Informationen werden hier nur zum allgemeinen Verständnis bereitgestellt. Wir werden dem neuronalen Netz jedes Mal dieselben Fragen stellen und versuchen zu erkennen, wie genau es versteht, was der Benutzer von ihm will.
Qwen 2
Vor kurzem hat ein Entwicklerteam der Alibaba Group die zweite Version ihres generativen neuronalen Netzes Qwen vorgestellt. Es versteht 27 Sprachen und ist für diese Sprachen gut optimiert. Qwen 2 gibt es in verschiedenen Größen, damit es auf jedem Gerät eingesetzt werden kann (von stark ressourcenbeschränkten eingebetteten Systemen bis hin zu einem dedizierten Server mit GPUs):
- 0.5B: geeignet für IoT und eingebettete Systeme;
- 1.5B: eine erweiterte Version für eingebettete Systeme, die eingesetzt wird, wenn die Fähigkeiten von 0.5B nicht ausreichen;
- 7B: mittelgroßes Modell, gut geeignet für die Verarbeitung natürlicher Sprache;
- 57B: leistungsstarkes großes Modell, das für anspruchsvolle Anwendungen geeignet ist;
- 72B: das ultimative Qwen-2-Modell, das für die Lösung der komplexesten Probleme und die Verarbeitung großer Datenmengen konzipiert ist.
Die Versionen 0.5B und 1.5B wurden auf Datensätzen mit einer Kontextlänge von 32K trainiert. Die Versionen 7B und 72B wurden bereits auf den 128K-Kontext trainiert. Das Kompromissmodell 57B wurde auf Datensätzen mit einer Kontextlänge von 64K trainiert. Die Entwickler sehen Qwen 2 als Analogon zu Llama 3, das die gleichen Probleme lösen kann, aber viel schneller ist.
Llama 3
Die dritte Version des generativen neuronalen Netzes aus der MetaAI Llama-Familie wurde im April 2024 vorgestellt. Es wurde, anders als Qwen 2, in nur zwei Versionen veröffentlicht: 8B und 70B. Diese Modelle wurden als universelles Werkzeug für die Lösung vieler Probleme in verschiedenen Fällen positioniert. Es setzte den Trend zur Mehrsprachigkeit und Multimodalität fort und wurde gleichzeitig schneller als die Vorgängerversionen und unterstützt eine größere Kontextlänge.
Die Entwickler von Llama 3 haben versucht, die Modelle zu verfeinern, um den Anteil der statistischen Halluzinationen zu verringern und die Vielfalt der Antworten zu erhöhen. So ist Llama 3 durchaus in der Lage, praktische Ratschläge zu geben, beim Verfassen eines Geschäftsbriefs zu helfen oder über ein vom Benutzer vorgegebenes Thema zu spekulieren. Die Datensätze, auf denen die Llama 3-Modelle trainiert wurden, hatten eine Kontextlänge von 128K und mehr als 5% enthielten Daten in 30 Sprachen. Wie es in der Pressemitteilung heißt, wird die Generierungsleistung in Englisch jedoch deutlich höher sein als in allen anderen Sprachen.
Vergleich
NVIDIA® RTX™ A6000
Beginnen wir unsere Geschwindigkeitsmessungen mit der NVIDIA® RTX™ A6000 GPU, die auf der Ampere-Architektur basiert (nicht zu verwechseln mit der NVIDIA® RTX™ A6000 Ada). Diese Karte hat sehr bescheidene Eigenschaften, aber gleichzeitig verfügt sie über 48 GB VRAM, was es ihr ermöglicht, mit ziemlich großen neuronalen Netzwerkmodellen zu arbeiten. Leider sind die niedrige Taktrate und Bandbreite die Gründe für die geringe Inferenzgeschwindigkeit von Text-LLMs.
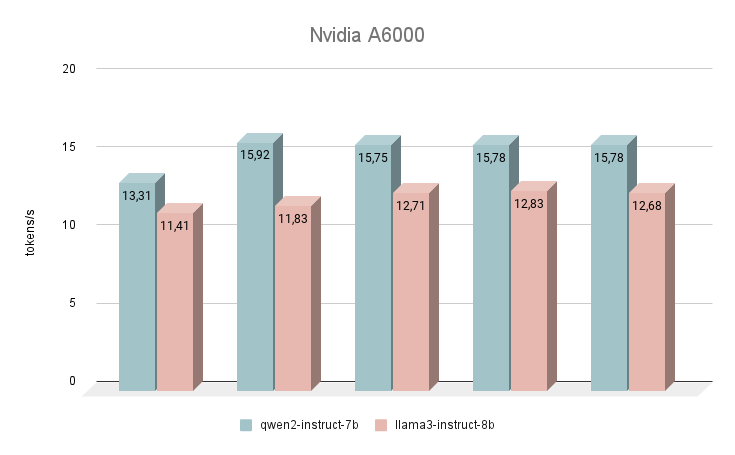
Unmittelbar nach dem Start begann das neuronale Netz Qwen 2, Llama 3 zu übertreffen. Bei der Beantwortung der gleichen Fragen betrug der durchschnittliche Geschwindigkeitsunterschied 24 % zugunsten von Qwen 2. Die Geschwindigkeit bei der Generierung von Antworten lag im Bereich von 11-16 Token pro Sekunde. Das ist 2-3 mal schneller als der Versuch, die Generierung selbst auf einer leistungsstarken CPU laufen zu lassen, aber in unserer Bewertung ist dies das bescheidenste Ergebnis.
NVIDIA® RTX™ 3090
Die nächste GPU basiert ebenfalls auf der Ampere-Architektur, hat 2 Mal weniger Videospeicher, arbeitet aber gleichzeitig mit einer höheren Frequenz (19500 MHz gegenüber 16000 Mhz). Auch die Bandbreite des Videospeichers ist höher (936,2 GB/s gegenüber 768 GB/s). Diese beiden Faktoren erhöhen die Leistung der RTX™ 3090 erheblich, selbst wenn man die Tatsache berücksichtigt, dass sie 256 CUDA-Kerne weniger hat.
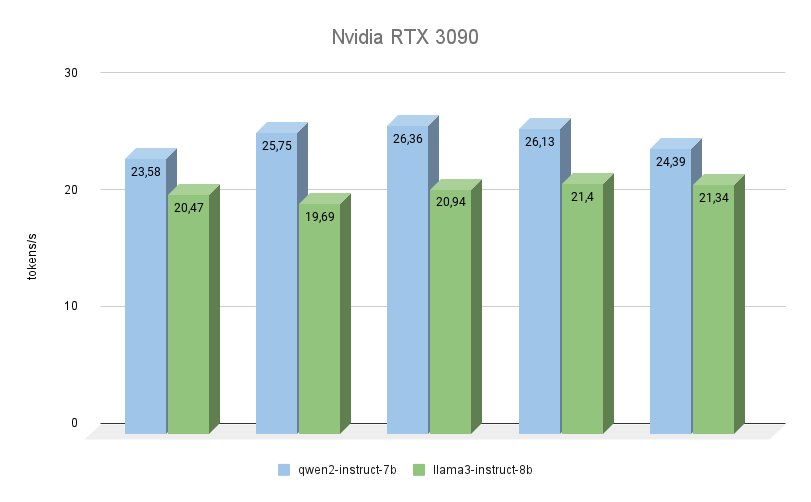
Hier kann man deutlich sehen, dass Qwen 2 bei der Ausführung der gleichen Aufgaben viel schneller ist (bis zu 23 %) als Llama 3. Was die Qualität der Generierung angeht, so ist die Mehrsprachenunterstützung von Qwen 3 wirklich lobenswert, und das Modell antwortet immer in der gleichen Sprache, in der die Frage gestellt wurde. Bei Llama 3 kommt es in dieser Hinsicht oft vor, dass das Modell zwar die Frage selbst versteht, es aber vorzieht, die Antworten auf Englisch zu formulieren.
NVIDIA® RTX™ 4090
Nun das Interessanteste: Schauen wir uns an, wie der NVIDIA® RTX™ 4090, der auf der Ada Lovelace Architektur basiert, benannt nach der englischen Mathematikerin Augusta Ada King, Countess of Lovelace, die gleiche Aufgabe bewältigt. Sie wurde berühmt, weil sie die erste Programmiererin in der Geschichte der Menschheit war, und als sie ihr erstes Programm schrieb, gab es noch keinen zusammengebauten Computer, der es ausführen konnte. Es wurde jedoch anerkannt, dass der von Ada beschriebene Algorithmus zur Berechnung der Bernoulli-Zahlen das erste Programm der Welt war, das für die Ausführung auf einem Computer geschrieben wurde.
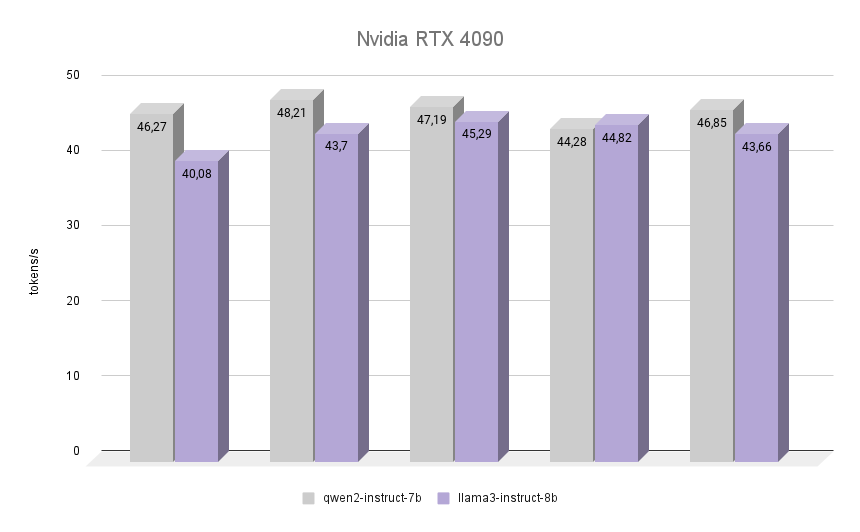
Die Grafik zeigt deutlich, dass der RTX™ 4090 die Inferenz beider Modelle fast doppelt so schnell bewältigte. Interessant ist, dass Llama 3 in einer der Iterationen die Leistung von Qwen 2 um 1,2 % übertreffen konnte. Berücksichtigt man jedoch die anderen Iterationen, so behielt Qwen 2 seine Führungsposition und blieb 7% schneller als Llama 3. In allen Iterationen war die Qualität der Antworten beider neuronaler Netze hoch, mit einer minimalen Anzahl von Halluzinationen. Der einzige Mangel ist, dass in seltenen Fällen ein oder zwei chinesische Zeichen in die Antworten gemischt wurden, was die Gesamtbedeutung in keiner Weise beeinträchtigte.
NVIDIA® RTX™ A40
Die nächste NVIDIA® RTX™ A40 Karte, mit der wir ähnliche Tests durchgeführt haben, basiert ebenfalls auf der Ampere-Architektur und verfügt über 48 GB Videospeicher auf dem Motherboard. Im Vergleich zur RTX™ 3090 ist dieser Speicher etwas schneller (20000 MHz vs. 19500 MHz), hat aber eine geringere Bandbreite (695,8 GB/s vs. 936,2 GB/s). Diese Situation wird durch die größere Anzahl an CUDA-Kernen (10752 gegenüber 10496) kompensiert, wodurch die RTX™ A40 insgesamt etwas schneller als die RTX™ 3090 arbeiten kann.
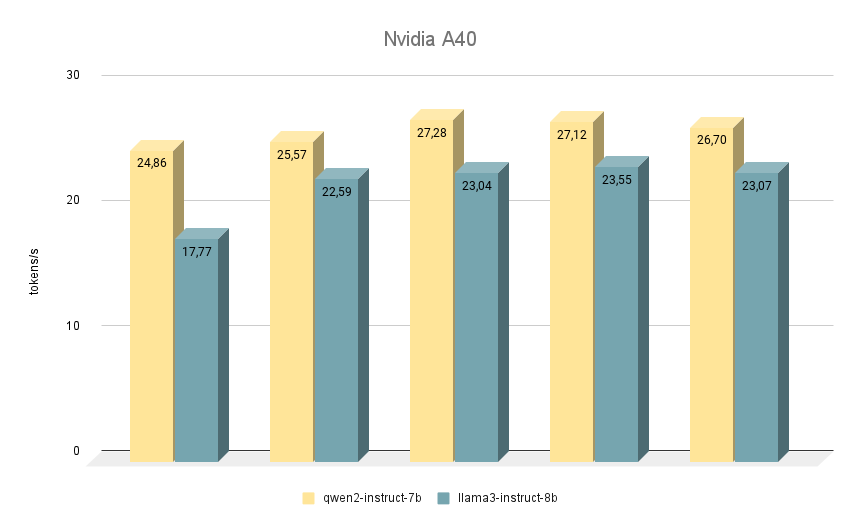
Was den Vergleich der Geschwindigkeit der Modelle angeht, so liegt Qwen 2 auch hier in allen Iterationen vor Llama 3. Wenn es auf der RTX™ A40 läuft, beträgt der Geschwindigkeitsunterschied bei den gleichen Antworten etwa 15 %. Bei einigen Aufgaben gab Qwen 2 etwas mehr wichtige Informationen, während Llama 3 so spezifisch wie möglich war und Beispiele gab. Trotzdem muss alles doppelt geprüft werden, da beide Modelle manchmal zu widersprüchlichen Antworten kommen.
NVIDIA® L20
Der letzte Teilnehmer in unserem Test war die NVIDIA® L20. Diese GPU ist wie die RTX™ 4090 auf der Ada Lovelace Architektur aufgebaut. Es handelt sich um ein relativ neues Modell, das im Herbst 2023 vorgestellt wurde. Es hat 48 GB Videospeicher und 11776 CUDA-Kerne an Bord. Die Speicherbandbreite ist geringer als bei der RTX™ 4090 (864 GB/s gegenüber 936,2 GB/s), ebenso die effektive Frequenz. Die NVIDIA® L20-Inferenzergebnisse beider Modelle werden also näher an 3090 als an 4090 liegen.
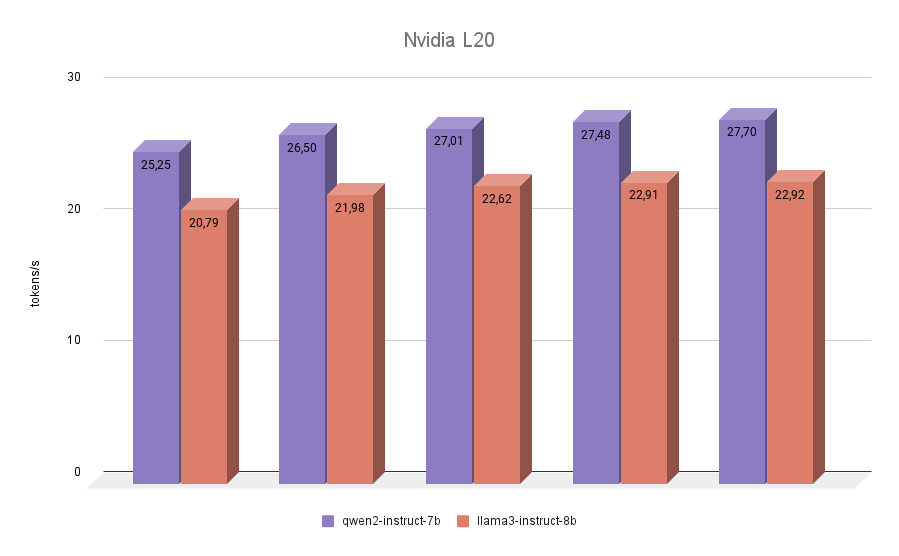
Der letzte Test brachte keine Überraschungen mehr. Qwen 2 erwies sich in allen Iterationen als schneller als Llama 3.
Fazit
Fassen wir alle gesammelten Ergebnisse in einem Diagramm zusammen. Qwen 2 war zwischen 7% und 24% schneller als Llama 3, abhängig von der verwendeten GPU. Daraus können wir eindeutig schließen, dass die RTX™ 3090 der unbestrittene Spitzenreiter ist, wenn es darum geht, Hochgeschwindigkeits-Inferenzen aus Modellen wie Qwen 2 oder Llama 3 auf Single-GPU-Konfigurationen zu erhalten. Eine mögliche Alternative könnte die A40 oder L20 sein. Aber es lohnt sich nicht, die Inferenz dieser Modelle auf Ampere-Karten der A6000-Generation laufen zu lassen.

Karten mit einem kleineren Videospeicher, wie z.B. NVIDIA® RTX™ 2080Ti, haben wir absichtlich nicht in den Tests erwähnt, da es nicht möglich ist, die oben erwähnten 7B- oder 8B-Modelle dort ohne Quantisierung unterzubringen. Nun, das 1.5B-Modell Qwen 2 hat leider keine hochwertigen Antworten und kann nicht als vollständiger Ersatz für 7B dienen.
Siehe auch:
Aktualisiert: 04.01.2026
Veröffentlicht: 20.01.2025




