





Ihr eigenes Qwen mit HF

Große neuronale Netzwerkmodelle mit ihren außergewöhnlichen Fähigkeiten sind fest in unserem Leben verankert. Große Unternehmen erkannten dies als Chance für die zukünftige Entwicklung und begannen, ihre eigenen Versionen dieser Modelle zu entwickeln. Der chinesische Gigant Alibaba hat nicht tatenlos zugesehen. Er entwickelte sein eigenes Modell, QWen (Tongyi Qianwen), das zur Grundlage für viele andere neuronale Netzwerkmodelle wurde.
Voraussetzungen
Cache und Pakete aktualisieren
Bevor Sie mit der Einrichtung von Qwen beginnen, sollten Sie den Paket-Cache aktualisieren und Ihr Betriebssystem aufrüsten. Außerdem müssen wir Python Installer Packages (PIP) hinzufügen, falls es nicht bereits im System vorhanden ist. Bitte beachten Sie, dass wir für diese Anleitung Ubuntu 22.04 LTS als Betriebssystem verwenden:
sudo apt update && sudo apt -y upgrade && sudo apt install python3-pipNvidia-Treiber installieren
Sie können das automatische Dienstprogramm verwenden, das in Ubuntu-Distributionen standardmäßig enthalten ist:
sudo ubuntu-drivers autoinstallAlternativ können Sie die Nvidia-Treiber auch manuell mit Hilfe unserer Schritt-für-Schritt-Anleitung installieren. Vergessen Sie nicht, den Server neu zu starten:
sudo shutdown -r nowTexterstellung Web UI
Klonen Sie das Repository
Öffnen Sie das Arbeitsverzeichnis auf der SSD:
cd /mnt/fastdiskKlonen Sie das Repository des Projekts:
git clone https://github.com/oobabooga/text-generation-webui.gitAnforderungen installieren
Öffnen Sie das heruntergeladene Verzeichnis:
cd text-generation-webuiÜberprüfen und installieren Sie alle fehlenden Komponenten:
pip install -r requirements.txtSSH-Schlüssel zu HF hinzufügen
Bevor Sie beginnen, müssen Sie in Ihrem SSH-Client eine Portweiterleitung einrichten (Remote-Port 7860 auf 127.0.0.1:7860). Weitere Informationen finden Sie im folgenden Artikel: Verbindung zum Linux-Server herstellen.
Aktualisieren Sie das Paket-Cache-Repository und die installierten Pakete:
sudo apt update && sudo apt -y upgradeErzeugen Sie einen SSH-Schlüssel, den Sie in Hugging Face verwenden können, und fügen Sie ihn hinzu:
cd ~/.ssh && ssh-keygenWenn das Schlüsselpaar generiert ist, können Sie den öffentlichen Schlüssel im Terminalemulator anzeigen:
cat id_rsa.pubKopieren Sie alle Informationen, die mit ssh-rsa beginnen und mit usergpu@gpuserver enden, wie im folgenden Screenshot gezeigt:
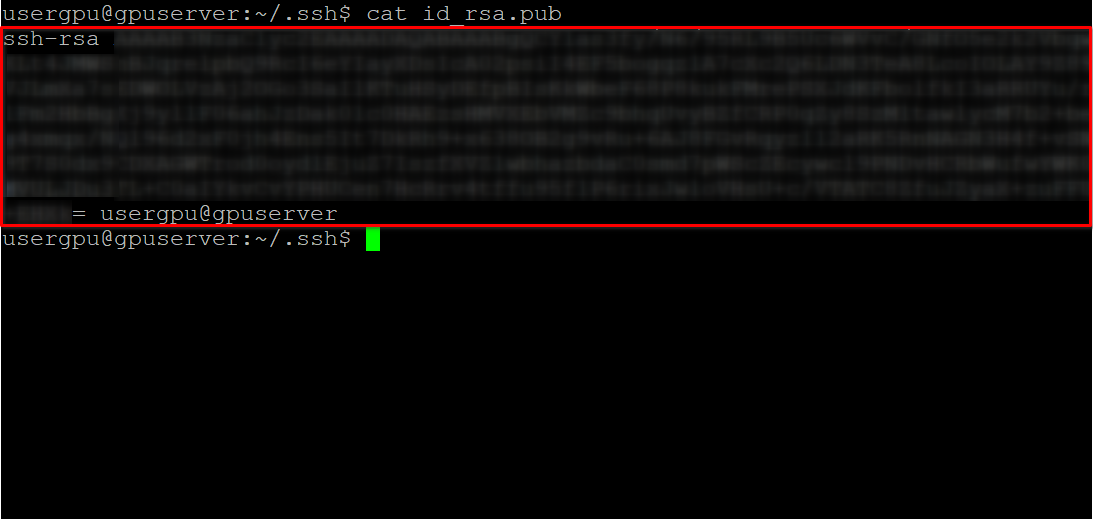
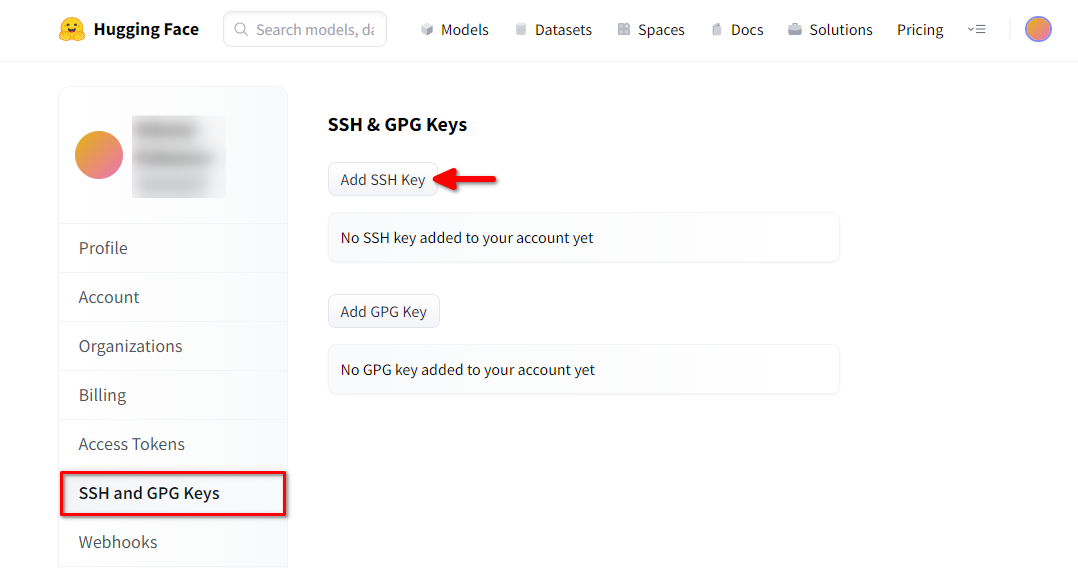
Öffnen Sie einen Webbrowser, geben Sie https://huggingface.co/ in die Adresszeile ein und drücken Sie Enter. Loggen Sie sich in Ihren HF-Account ein und öffnen Sie die Profileinstellungen. Wählen Sie dann SSH and GPG Keys und klicken Sie auf die Schaltfläche Add SSH Key:
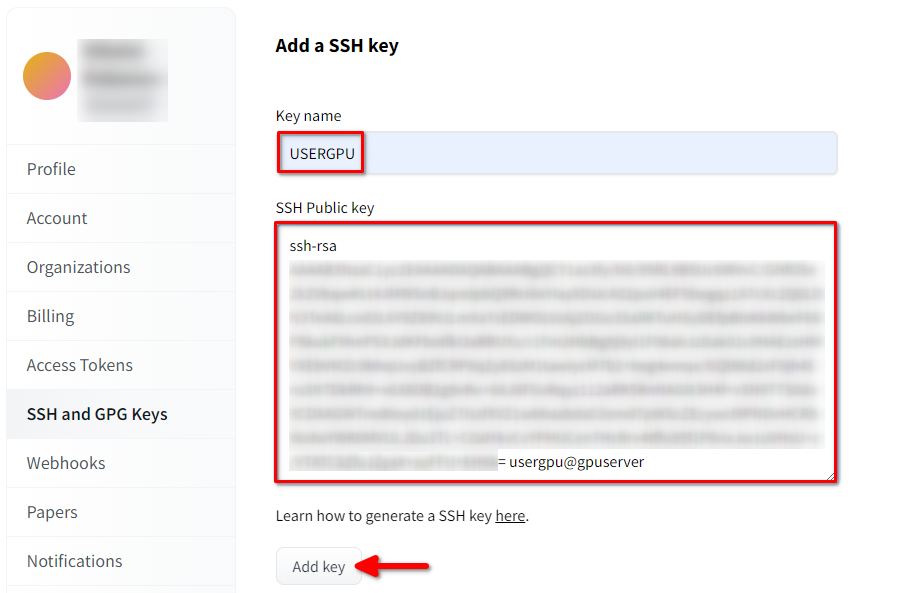
Füllen Sie Key name aus und fügen Sie den kopierten SSH Public key aus dem Terminal ein. Speichern Sie den Schlüssel, indem Sie Add key drücken:
Jetzt ist Ihr HF-Konto mit dem öffentlichen SSH-Schlüssel verknüpft. Der zweite Teil (privater Schlüssel) ist auf dem Server gespeichert. Der nächste Schritt ist die Installation einer speziellen Git LFS-Erweiterung (Large File Storage), die für das Herunterladen großer Dateien wie z. B. Modelle neuronaler Netze verwendet wird. Öffnen Sie Ihr Home-Verzeichnis:
cd ~/Laden Sie das Shell-Skript herunter und führen Sie es aus. Dieses Skript installiert ein neues Drittanbieter-Repository mit git-lfs:
curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bashNun können Sie es mit dem Standard-Paketmanager installieren:
sudo apt-get install git-lfsLassen Sie uns git so konfigurieren, dass es unseren HF-Nickname verwendet:
git config --global user.name "John"Und mit dem HF-E-Mail-Konto verknüpft:
git config --global user.email "john.doe@example.com"Das Modell herunterladen
Der nächste Schritt ist das Herunterladen des Modells mit der von Softwareentwicklern häufig verwendeten Technik des Klonens von Repositorys. Der einzige Unterschied besteht darin, dass das zuvor installierte Git-LFS die markierten Zeigerdateien automatisch verarbeiten und den gesamten Inhalt herunterladen wird. Öffnen Sie das erforderliche Verzeichnis (in unserem Beispiel /mnt/fastdisk):
cd /mnt/fastdiskDieser Befehl kann einige Zeit in Anspruch nehmen:
git clone git@hf.co:Qwen/Qwen1.5-32B-Chat-GGUFAusführen des Modells
Führen Sie ein Skript aus, das den Webserver startet und /mnt/fastdisk als das Arbeitsverzeichnis mit den Modellen angibt. Dieses Skript kann beim ersten Start einige zusätzliche Komponenten herunterladen.
./start_linux.sh --model-dir /mnt/fastdiskÖffnen Sie Ihren Webbrowser und wählen Sie llama.cpp aus der Dropdown-Liste Model loader:
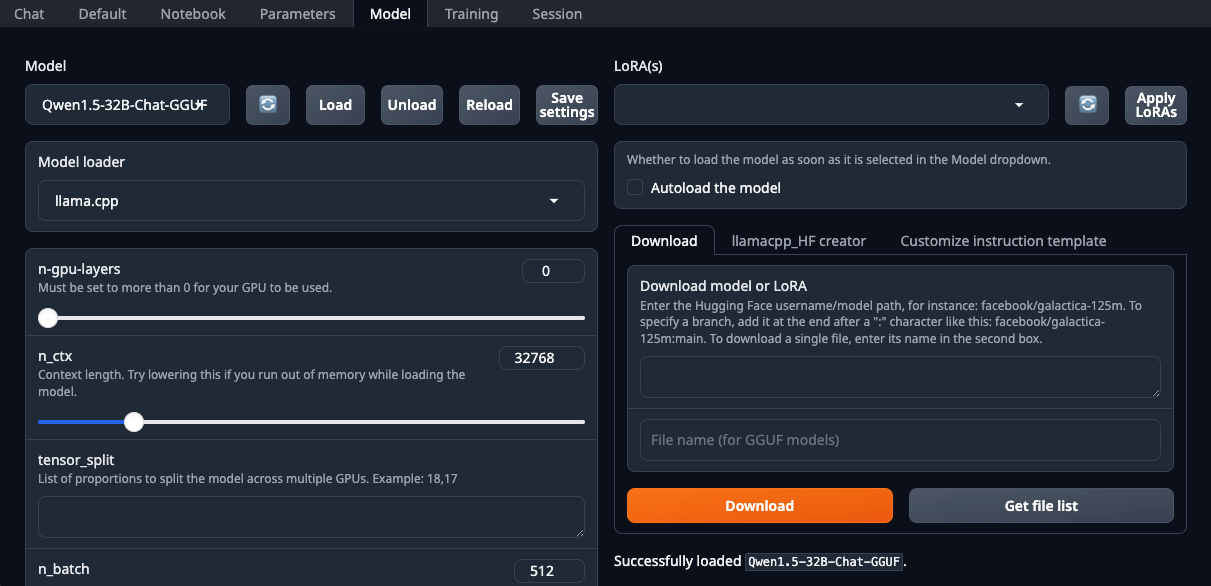
Stellen Sie sicher, dass Sie den Parameter n-gpu-layers setzen. Er ist dafür verantwortlich, wie viel Prozent der Berechnungen auf den Grafikprozessor verlagert werden. Wenn Sie die Zahl auf 0 belassen, werden alle Berechnungen auf der CPU durchgeführt, was ziemlich langsam ist. Sobald alle Parameter eingestellt sind, klicken Sie auf die Schaltfläche Load. Wechseln Sie dann zur Registerkarte Chat und wählen Sie Instruct mode. Nun können Sie eine beliebige Eingabeaufforderung eingeben und eine Antwort erhalten:
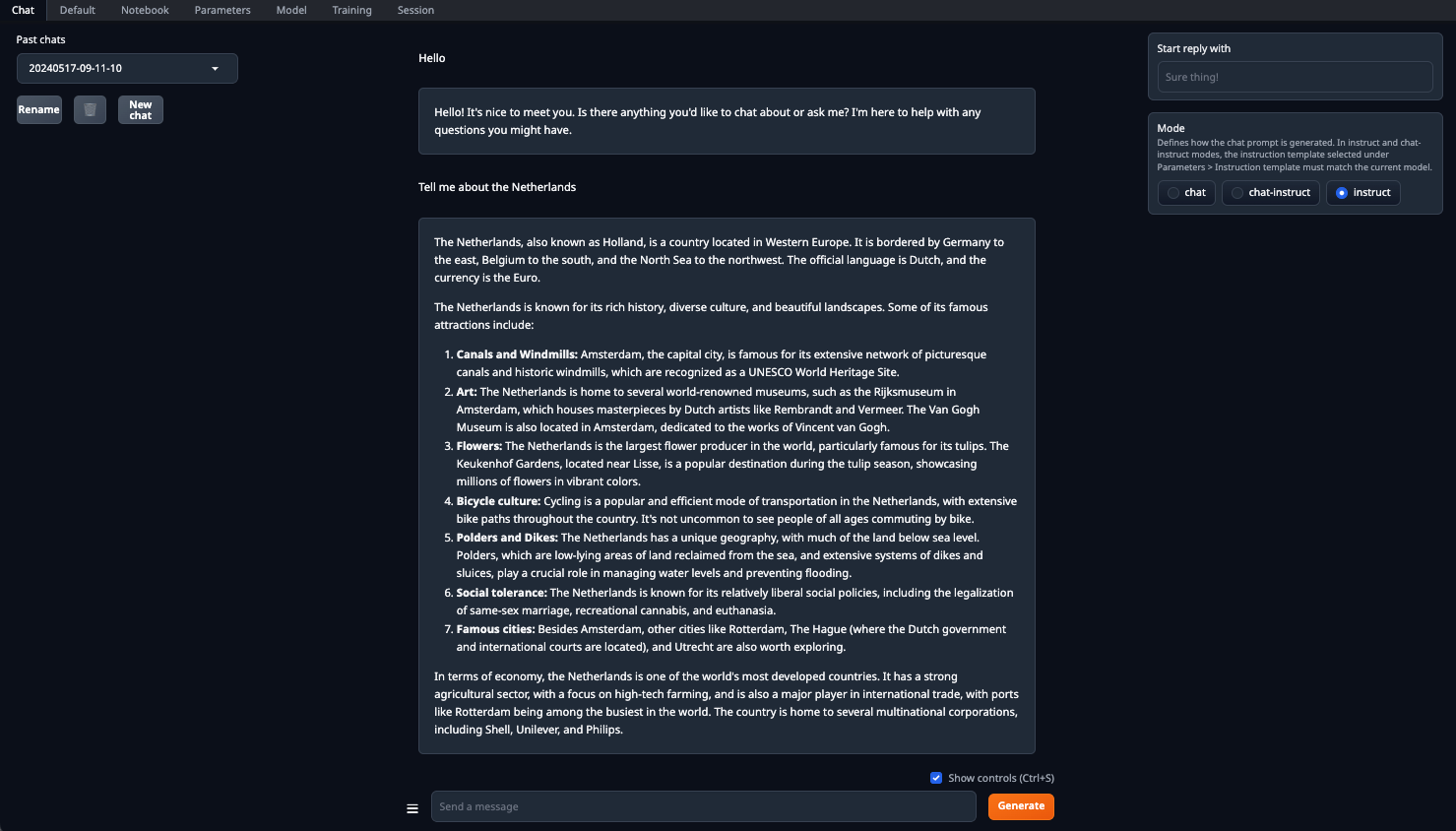
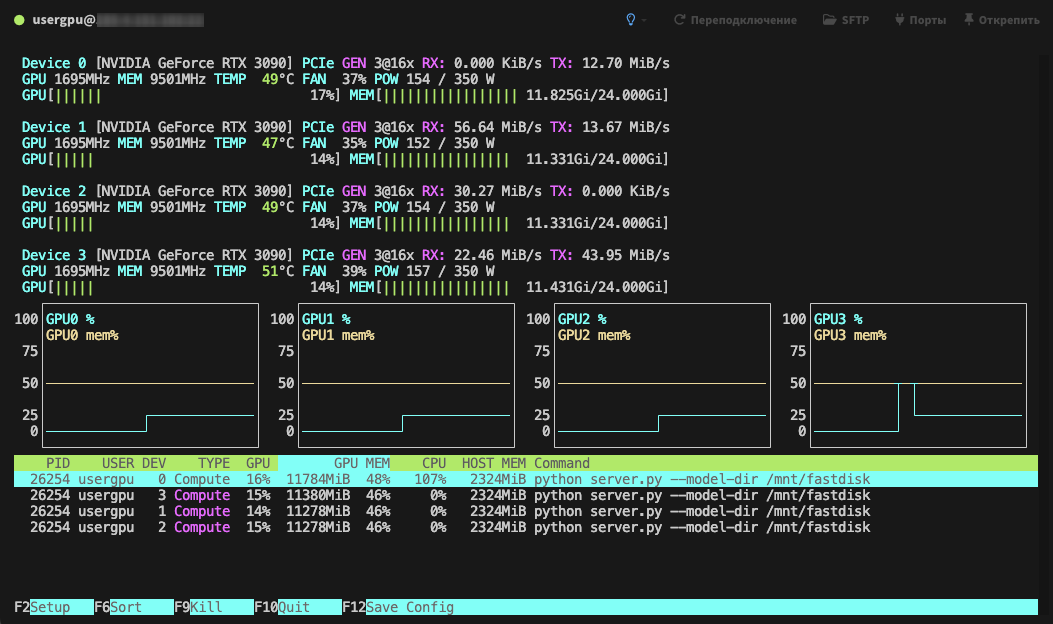
Die Verarbeitung wird standardmäßig auf allen verfügbaren GPUs durchgeführt, wobei die zuvor festgelegten Parameter berücksichtigt werden:
Siehe auch:
Aktualisiert: 04.01.2026
Veröffentlicht: 20.01.2025




