





Was ist Wissensdestillation?
Große Sprachmodelle (Large Language Models, LLMs) sind durch ihre einzigartigen Fähigkeiten zu einem festen Bestandteil unseres Lebens geworden. Sie verstehen den Kontext und erstellen darauf aufbauend kohärente, umfassende Texte. Sie können jede Sprache verarbeiten und in jeder Sprache reagieren und dabei die kulturellen Nuancen jeder Sprache berücksichtigen.
LLMs sind hervorragend in der Lage, komplexe Probleme zu lösen, zu programmieren, Konversationen zu führen und vieles mehr. Diese Vielseitigkeit ergibt sich aus der Verarbeitung großer Mengen von Trainingsdaten, daher der Begriff "groß". Diese Modelle können Dutzende oder Hunderte von Milliarden von Parametern enthalten, was sie für den täglichen Gebrauch sehr ressourcenintensiv macht.
Das Training ist der anspruchsvollste Prozess. Neuronale Netzmodelle lernen, indem sie riesige Datensätze verarbeiten und ihre internen "Gewichte" anpassen, um stabile Verbindungen zwischen den Neuronen zu bilden. Diese Verbindungen speichern Wissen, das das trainierte neuronale Netz später auf Endgeräten verwenden kann.
Den meisten Endgeräten fehlt jedoch die nötige Rechenleistung, um diese Modelle auszuführen. Um beispielsweise die Vollversion von Llama 2 (70B Parameter) auszuführen, ist ein Grafikprozessor mit 48 GB Videospeicher erforderlich - Hardware, die nur wenige Nutzer zu Hause haben, geschweige denn auf mobilen Geräten.
Daher arbeiten die meisten modernen neuronalen Netze in einer Cloud-Infrastruktur und nicht auf tragbaren Geräten, die über APIs auf sie zugreifen. Dennoch machen die Gerätehersteller in zweierlei Hinsicht Fortschritte: Sie statten ihre Geräte mit spezialisierten Recheneinheiten wie NPUs aus und entwickeln Methoden zur Verbesserung der Leistung kompakter neuronaler Netzwerkmodelle.
Verkleinerung der Größe
Überflüssiges abschneiden
Die Quantisierung ist die erste und wirksamste Methode zur Reduzierung der Größe eines neuronalen Netzes. Die Gewichte neuronaler Netze verwenden normalerweise 32-Bit-Gleitkommazahlen, aber wir können sie verkleinern, indem wir dieses Format ändern. Die Verwendung von 8-Bit-Werten (oder in manchen Fällen sogar von binären Einsen) kann die Größe des Netzwerks um das Zehnfache reduzieren, was jedoch die Genauigkeit der Antworten erheblich verringert.
Pruning ist ein weiterer Ansatz, bei dem unwichtige Verbindungen im neuronalen Netz entfernt werden. Dieser Prozess funktioniert sowohl während des Trainings als auch bei abgeschlossenen Netzen. Beim Pruning können nicht nur Verbindungen, sondern auch Neuronen oder ganze Schichten entfernt werden. Diese Reduzierung der Parameter und Verbindungen führt zu einem geringeren Speicherbedarf.
Die Matrix- oder Tensorzerlegung ist die dritte gängige Technik zur Größenreduzierung. Durch die Zerlegung einer großen Matrix in ein Produkt aus drei kleineren Matrizen werden die Gesamtparameter bei gleichbleibender Qualität reduziert. Dadurch kann die Größe des Netzes um das Dutzendfache verringert werden. Die Tensoredekomposition bietet sogar noch bessere Ergebnisse, erfordert jedoch mehr Hyperparameter.
Während diese Methoden die Größe effektiv reduzieren, stehen sie alle vor dem Problem des Qualitätsverlustes. Große komprimierte Modelle übertreffen ihre kleineren, nicht komprimierten Gegenstücke, aber jede Komprimierung birgt das Risiko, die Genauigkeit der Antworten zu verringern. Die Wissensdestillation stellt einen interessanten Versuch dar, Qualität und Größe in Einklang zu bringen.
Lassen Sie es uns gemeinsam versuchen
Die Wissensdestillation lässt sich am besten durch die Analogie zwischen einem Schüler und einem Lehrer erklären. Während die Schüler lernen, lehren die Lehrer und aktualisieren auch ständig ihr vorhandenes Wissen. Wenn beide mit neuem Wissen konfrontiert werden, hat der Lehrer einen Vorteil: Er kann auf sein breites Wissen aus anderen Bereichen zurückgreifen, während dem Schüler diese Grundlage noch fehlt.
Dieses Prinzip gilt auch für neuronale Netze. Wenn zwei neuronale Netze desselben Typs, aber unterschiedlicher Größe, mit identischen Daten trainiert werden, schneidet das größere Netz in der Regel besser ab. Seine größere Kapazität an "Wissen" ermöglicht genauere Antworten als sein kleineres Gegenstück. Daraus ergibt sich eine interessante Möglichkeit: Warum trainiert man das kleinere Netz nicht nur mit dem Datensatz, sondern auch mit den genaueren Ergebnissen des größeren Netzes?
Dieser Prozess ist die Wissensdestillation: eine Form des überwachten Lernens, bei der ein kleineres Modell lernt, die Vorhersagen eines größeren Modells zu replizieren. Diese Technik hilft zwar, den Qualitätsverlust auszugleichen, der durch die Verkleinerung des neuronalen Netzes entsteht, erfordert aber zusätzliche Rechenressourcen und Trainingszeit.
Software und Logik
Nachdem nun die theoretischen Grundlagen geklärt sind, wollen wir den Prozess aus technischer Sicht untersuchen. Wir beginnen mit Software-Tools, die Sie durch die Phasen des Trainings und der Wissensdestillation führen können.
Python bietet zusammen mit der TorchTune-Bibliothek aus dem PyTorch-Ökosystem den einfachsten Ansatz für die Untersuchung und Feinabstimmung großer Sprachmodelle. So funktioniert die Anwendung:
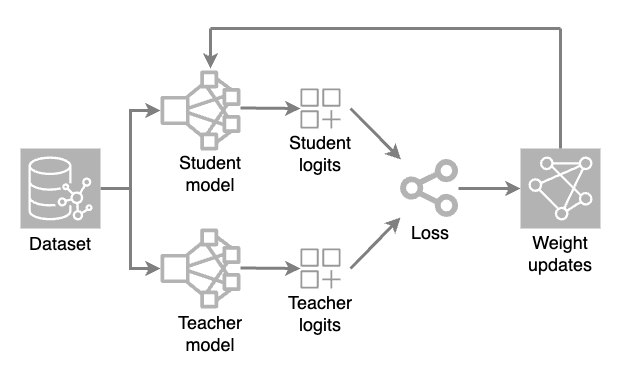
Es werden zwei Modelle geladen: ein vollständiges Modell (Lehrer) und ein reduziertes Modell (Schüler). Während jeder Trainingsiteration erzeugt das Lehrermodell Hochtemperaturvorhersagen, während das Schülermodell den Datensatz verarbeitet, um seine eigenen Vorhersagen zu treffen.
Die rohen Ausgabewerte (Logits) beider Modelle werden anhand einer Verlustfunktion (ein numerisches Maß dafür, wie stark eine Vorhersage vom richtigen Wert abweicht) bewertet. Die Gewichtungsanpassungen werden dann durch Backpropagation auf das Studentenmodell angewendet. Dadurch kann das kleinere Modell lernen und die Vorhersagen des Lehrermodells replizieren.
Die wichtigste Konfigurationsdatei im Anwendungscode wird als Rezept bezeichnet. In dieser Datei werden alle Destillationsparameter und -einstellungen gespeichert, so dass die Experimente reproduzierbar sind und die Forscher verfolgen können, wie die verschiedenen Parameter das Endergebnis beeinflussen.
Bei der Auswahl der Parameterwerte und der Anzahl der Iterationen ist die Wahrung des Gleichgewichts entscheidend. Ein Modell, das zu stark destilliert wurde, kann seine Fähigkeit verlieren, subtile Details und den Kontext zu erkennen, und zu schablonenhaften Antworten übergehen. Auch wenn ein perfektes Gleichgewicht kaum zu erreichen ist, kann eine sorgfältige Überwachung des Destillationsprozesses die Vorhersagequalität selbst bescheidener neuronaler Netzwerkmodelle erheblich verbessern.
Auch während des Trainingsprozesses lohnt es sich, auf die Überwachung zu achten. So können Probleme rechtzeitig erkannt und umgehend korrigiert werden. Hierfür können Sie das TensorBoard-Tool verwenden. Es lässt sich nahtlos in PyTorch-Projekte integrieren und ermöglicht die visuelle Auswertung vieler Metriken, wie Genauigkeit und Verluste. Außerdem können Sie damit einen Modellgraphen erstellen, die Speichernutzung und die Ausführungszeit von Operationen verfolgen.
Schlussfolgerung
Wissensdestillation ist eine effektive Methode zur Optimierung neuronaler Netze, um kompakte Modelle zu verbessern. Sie funktioniert am besten, wenn ein Gleichgewicht zwischen Leistung und Antwortqualität wichtig ist.
Obwohl die Wissensdestillation eine sorgfältige Überwachung erfordert, können ihre Ergebnisse bemerkenswert sein. Die Modelle werden bei gleichbleibender Vorhersagequalität wesentlich kleiner und erzielen mit weniger Rechenressourcen eine bessere Leistung.
Bei einer guten Planung mit geeigneten Parametern ist die Wissensdestillation ein wichtiges Instrument zur Erstellung kompakter neuronaler Netze ohne Qualitätseinbußen.
Siehe auch:
Aktualisiert: 04.01.2026
Veröffentlicht: 23.01.2025




