





Wie funktioniert Ollama?

Ollama ist ein Werkzeug für die lokale Ausführung großer neuronaler Netzmodelle. Die Nutzung öffentlicher Dienste wird von Unternehmen oft als potenzielles Risiko für den Verlust vertraulicher und sensibler Daten wahrgenommen. Der Einsatz von LLM auf einem kontrollierten Server ermöglicht es Ihnen daher, die darauf abgelegten Daten unabhängig zu verwalten und gleichzeitig die Stärken von LLM zu nutzen.
Dies hilft auch, die unangenehme Situation der Anbieterbindung zu vermeiden, bei der jeder öffentliche Dienst einseitig die Bereitstellung von Diensten einstellen kann. Natürlich besteht das ursprüngliche Ziel darin, die Nutzung generativer neuronaler Netze an Orten zu ermöglichen, an denen kein oder nur ein eingeschränkter Internetzugang besteht (z. B. in einem Flugzeug).
Die Idee war, den Start, die Steuerung und die Feinabstimmung von LLMs zu vereinfachen. Anstelle komplexer mehrstufiger Anweisungen ermöglicht Ollama die Ausführung eines einfachen Befehls, und nach einiger Zeit erhält man das fertige Ergebnis. Es wird gleichzeitig in Form eines lokalen neuronalen Netzmodells präsentiert, mit dem Sie über eine Webschnittstelle und eine API zur einfachen Integration in andere Anwendungen kommunizieren können.
Für viele Entwickler wurde dies zu einem sehr nützlichen Werkzeug, da es in den meisten Fällen möglich war, Ollama in die verwendete IDE zu integrieren und Empfehlungen oder vorgefertigten Code direkt während der Arbeit an der Anwendung zu erhalten.
Ollama war ursprünglich nur für Computer mit dem Betriebssystem macOS gedacht, wurde aber später auf Linux und Windows portiert. Es wurde auch eine spezielle Version für die Arbeit in containerisierten Umgebungen wie Docker veröffentlicht. Derzeit funktioniert es sowohl auf Desktops als auch auf jedem dedizierten Server mit einer GPU gleichermaßen gut. Ollama unterstützt die Fähigkeit, zwischen verschiedenen Modellen umzuschalten, und maximiert alle verfügbaren Ressourcen. Natürlich sind diese Modelle auf einem normalen Desktop nicht ganz so leistungsfähig, aber sie funktionieren durchaus angemessen.
Wie installiert man Ollama?
Ollama kann auf zwei Arten installiert werden: ohne Containerisierung, mit einem Installationsskript, und als fertiger Docker-Container. Die erste Methode macht es einfacher, die Komponenten des installierten Systems und der Modelle zu verwalten, ist aber weniger fehlertolerant. Die zweite Methode ist fehlertoleranter, aber bei ihrer Verwendung müssen Sie alle Aspekte berücksichtigen, die mit Containern verbunden sind: eine etwas komplexere Verwaltung und ein anderer Ansatz für die Datenspeicherung.
Unabhängig von der gewählten Methode sind mehrere zusätzliche Schritte zur Vorbereitung des Betriebssystems erforderlich.
Voraussetzungen
Aktualisieren Sie das Paket-Cache-Repository und die installierten Pakete:
sudo apt update && sudo apt -y upgradeInstallieren Sie alle erforderlichen GPU-Treiber mit der automatischen Installationsfunktion:
sudo ubuntu-drivers autoinstallStarten Sie den Server neu:
sudo shutdown -r nowInstallation über Skript
Das folgende Skript erkennt die aktuelle Architektur des Betriebssystems und installiert die entsprechende Version von Ollama:
curl -fsSL https://ollama.com/install.sh | shWährend des Betriebs legt das Skript einen eigenen Benutzer ollama an, unter dem der entsprechende Daemon gestartet wird. Das gleiche Skript funktioniert übrigens auch in WSL2 und ermöglicht die Installation der Linux-Version von Ollama auf Windows Server.
Installation über Docker
Es gibt verschiedene Methoden, die Docker-Engine auf einem Server zu installieren. Der einfachste Weg ist die Verwendung eines speziellen Skripts, das die aktuelle Docker-Version installiert. Dieser Ansatz ist für Ubuntu Linux ab Version 20.04 (LTS) bis zur neuesten Version, Ubuntu 24.04 (LTS), wirksam:
curl -sSL https://get.docker.com/ | shDamit Docker-Container richtig mit der GPU interagieren können, muss ein zusätzliches Toolkit installiert werden. Da es nicht in den grundlegenden Ubuntu-Repositories verfügbar ist, müssen Sie zunächst ein Drittanbieter-Repository mit dem folgenden Befehl hinzufügen:
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.listAktualisieren Sie das Paket-Cache-Repository:
sudo apt updateUnd installieren Sie das Paket nvidia-container-toolkit:
sudo apt install nvidia-container-toolkitVergessen Sie nicht, den Docker-Daemon über systemctl neu zu starten:
sudo systemctl restart dockerEs ist an der Zeit, Ollama herunterzuladen und mit der Open-WebUI-Weboberfläche zu starten:
sudo docker run -d -p 3000:8080 --gpus=all -v ollama:/root/.ollama -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:ollamaÖffnen Sie den Webbrowser und navigieren Sie zu http://[server-ip]:3000:
Herunterladen und Ausführen der Modelle
Über die Befehlszeile
Führen Sie einfach den folgenden Befehl aus:
ollama run llama3Über die WebUI
Öffnen Sie Settings > Models, geben Sie den gewünschten Modellnamen ein, z. B. llama3 und klicken Sie auf die Schaltfläche mit dem Download-Symbol:

Das Modell wird automatisch heruntergeladen und installiert. Sobald die Installation abgeschlossen ist, schließen Sie das Einstellungsfenster und wählen das heruntergeladene Modell aus. Danach können Sie einen Dialog mit dem Modell beginnen:

VSCode-Integration
Wenn Sie Ollama mit Hilfe des Installationsskripts installiert haben, können Sie jedes der unterstützten Modelle fast sofort starten. Im nächsten Beispiel werden wir das Standardmodell ausführen, das von der Ollama Autocoder-Erweiterung erwartet wird (openhermes2.5-mistral:7b-q4_K_M):
ollama run openhermes2.5-mistral:7b-q4_K_MStandardmäßig erlaubt Ollama die Arbeit über eine API, die nur Verbindungen vom lokalen Host zulässt. Daher ist vor der Installation und Verwendung der Erweiterung für Visual Studio Code eine Portweiterleitung erforderlich. Insbesondere müssen Sie den Remote-Port 11434 an Ihren lokalen Computer weiterleiten. Ein Beispiel für die Weiterleitung finden Sie in unserem Artikel über Easy Diffusion WebUI.
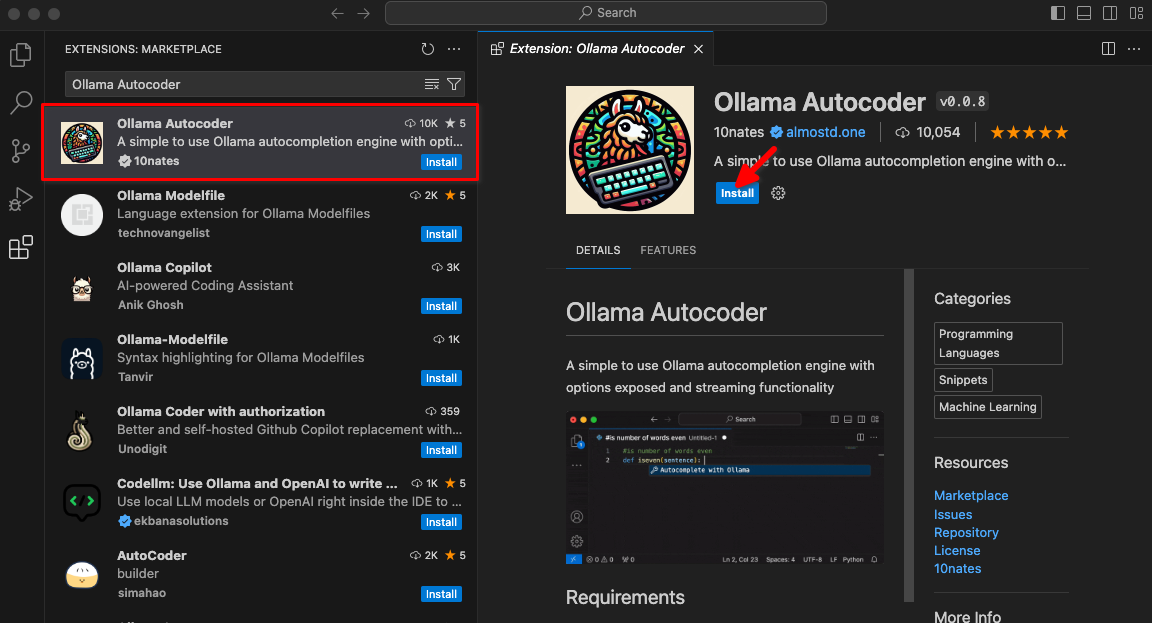
Geben Sie Ollama Autocoder in ein Suchfeld ein, und klicken Sie dann auf Install:
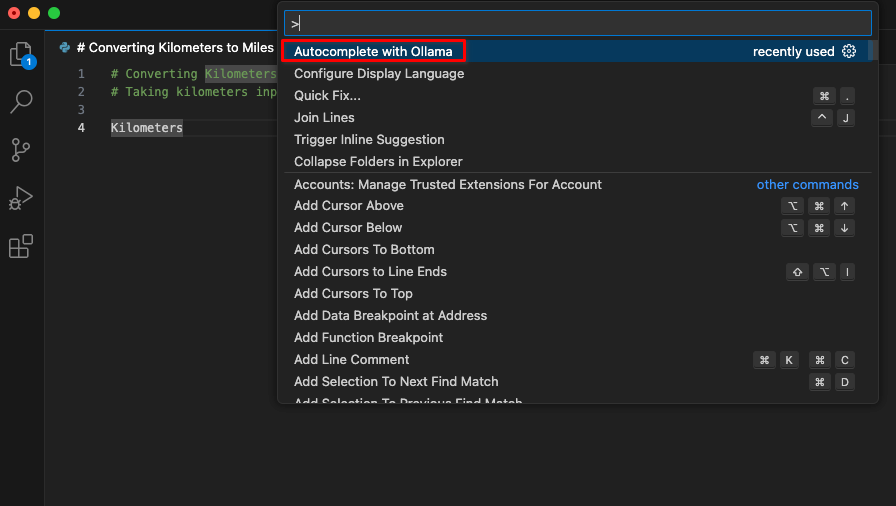
Nach der Installation der Erweiterung steht in der Befehlspalette ein neues Element mit dem Namen Autocomplete with Ollama zur Verfügung. Beginnen Sie mit der Codierung und initiieren Sie diesen Befehl.
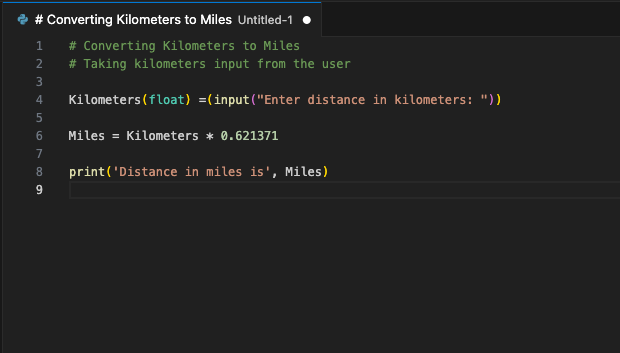
Die Erweiterung stellt eine Verbindung zum LeaderGPU-Server über Portweiterleitung her, und innerhalb weniger Sekunden wird der generierte Code auf Ihrem Bildschirm angezeigt:
Sie können diesen Befehl einem Hotkey zuweisen. Verwenden Sie ihn immer dann, wenn Sie Ihren Code durch ein generiertes Fragment ergänzen wollen. Dies ist nur ein Beispiel für die verfügbaren VSCode-Erweiterungen. Das Prinzip der Portweiterleitung von einem entfernten Server zu einem lokalen Computer ermöglicht es Ihnen, einen einzigen Server mit einem laufenden LLM für ein ganzes Entwicklerteam einzurichten. Diese Sicherheit verhindert, dass Drittfirmen oder Hacker den gesendeten Code verwenden.
Siehe auch:
Aktualisiert: 04.01.2026
Veröffentlicht: 20.01.2025




