





Qwen3-Coder: Ein gebrochenes Paradigma

Wir sind daran gewöhnt, dass Open-Source-Modelle in ihrer Qualität immer hinter ihren kommerziellen Pendants zurückbleiben. Es mag den Anschein haben, dass sie ausschließlich von Enthusiasten entwickelt werden, die es sich nicht leisten können, große Summen in die Erstellung hochwertiger Datensätze und das Training von Modellen auf Zehntausenden moderner Grafikprozessoren zu investieren.
Anders sieht es aus, wenn sich große Unternehmen wie OpenAI, Anthropic oder Meta dieser Aufgabe annehmen. Sie verfügen nicht nur über die nötigen Ressourcen, sondern auch über die weltweit besten Spezialisten für neuronale Netze. Leider sind die von ihnen erstellten Modelle, insbesondere die neuesten Versionen, Closed-Source. Die Entwickler begründen dies mit den Risiken einer unkontrollierten Nutzung und mit der Notwendigkeit, die Sicherheit der KI zu gewährleisten.
Einerseits ist ihre Argumentation nachvollziehbar: Viele ethische Fragen sind nach wie vor ungelöst, und die Natur der Modelle neuronaler Netze erlaubt nur eine indirekte Einflussnahme auf das Endergebnis. Andererseits ist es auch ein solides Geschäftsmodell, die Modelle geschlossen zu halten und den Zugang nur über die eigene API anzubieten.
Allerdings verhalten sich nicht alle Unternehmen auf diese Weise. Das französische Unternehmen Mistral AI beispielsweise bietet sowohl kommerzielle als auch Open-Source-Modelle an, die von Forschern und Enthusiasten für ihre Projekte genutzt werden können. Besonderes Augenmerk sollte jedoch auf die Leistungen chinesischer Unternehmen gelegt werden, von denen die meisten Modelle mit offenem Gewicht und offenem Quellcode entwickeln, die mit proprietären Lösungen ernsthaft konkurrieren können.
DeepSeek, Qwen3 und Kimi K2
Der erste große Durchbruch gelang mit DeepSeek-V3. Dieses multimodale Sprachmodell von DeepSeek AI wurde unter Verwendung des Mixture of Experts (MoE)-Ansatzes entwickelt und umfasst beeindruckende 671B Parameter, von denen 37B für jedes Token aktiviert sind. Am wichtigsten ist, dass alle Komponenten (Modellgewichte, Inferenzcode und Trainingspipelines) offengelegt wurden.
Dies machte es sofort zu einem der attraktivsten LLMs für Entwickler von KI-Anwendungen und Forscher gleichermaßen. Der nächste Schlagzeilenmacher war DeepSeek-R1 - das erste quelloffene Reasoning-Modell. Am Tag seiner Veröffentlichung erschütterte es die US-Börse, nachdem seine Entwickler behauptet hatten, dass das Training eines so fortschrittlichen Modells nur 6 Millionen Dollar gekostet hatte.
Während sich der Hype um DeepSeek schließlich abkühlte, waren die nächsten Veröffentlichungen nicht weniger wichtig für die globale KI-Branche. Die Rede ist natürlich von Qwen 3. Wir haben die Funktionen in unserem Bericht über Was ist neu in Qwen 3 ausführlich beschrieben, so dass wir hier nicht weiter darauf eingehen wollen. Kurz darauf tauchte ein weiterer Spieler auf: Kimi K2 von Moonshot AI.
Mit seiner MoE-Architektur, 1T-Parametern (32B pro Token aktiviert) und Open-Source-Code zog Kimi K2 schnell die Aufmerksamkeit der Community auf sich. Moonshot AI konzentrierte sich nicht auf das logische Denken, sondern strebte nach Spitzenleistungen in Mathematik, Programmierung und tiefgreifendem interdisziplinärem Wissen.
Das Ass im Ärmel von Kimi K2 war seine Optimierung für die Integration in KI-Agenten. Dieses Netzwerk wurde im wahrsten Sinne des Wortes so konzipiert, dass es alle verfügbaren Werkzeuge voll ausschöpfen kann. Es eignet sich hervorragend für Aufgaben, die nicht nur das Schreiben von Code, sondern auch iterative Tests in jeder Entwicklungsphase erfordern. Allerdings hat es auch Schwächen, auf die wir später noch eingehen werden.
Kimi K2 ist in jeder Hinsicht ein großes Sprachmodell. Die Ausführung der Vollversion erfordert ~2 TB VRAM (FP8: ~1 TB). Aus offensichtlichen Gründen ist das nichts, was man zu Hause machen kann, und selbst viele GPU-Server werden das nicht schaffen. Das Modell benötigt mindestens 8 NVIDIA® H200 Beschleuniger. Quantisierte Versionen können Abhilfe schaffen, allerdings zu einem spürbaren Preis für die Genauigkeit.
Qwen3-Coder
Angesichts des Erfolgs von Moonshot AI hat Alibaba sein eigenes, Kimi K2-ähnliches Modell entwickelt, allerdings mit erheblichen Vorteilen, auf die wir gleich eingehen werden. Ursprünglich wurde es in zwei Versionen veröffentlicht:
- Qwen3-Coder-480B-A35B-Instruct (~250 GB VRAM)
- Qwen3-Coder-480B-A35B-Instruct-FP8 (~120 GB VRAM)
Einige Tage später erschienen kleinere Modelle ohne den Argumentationsmechanismus, die weit weniger VRAM benötigten:
- Qwen3-Coder-30B-A3B-Instruct (~32 GB VRAM)
- Qwen3-Coder-30B-A3B-Instruct-FP8 (~18 GB VRAM)
Qwen3-Coder wurde für die Integration mit Entwicklungswerkzeugen konzipiert. Es enthält einen speziellen Parser für Funktionsaufrufe (qwen3coder_tool_parser.py, analog zu OpenAIs Funktionsaufruf). Zusammen mit dem Modell wurde ein Konsolenprogramm veröffentlicht, das von der Codekompilierung bis zur Abfrage einer Wissensdatenbank reicht. Diese Idee ist nicht neu, im Wesentlichen handelt es sich um eine stark überarbeitete Erweiterung der Gemini-Code-App von Anthropic.
Das Modell ist mit der OpenAI-API kompatibel, so dass es lokal oder auf einem entfernten Server eingesetzt und mit den meisten Systemen, die diese API unterstützen, verbunden werden kann. Dazu gehören sowohl vorgefertigte Client-Anwendungen als auch Bibliotheken für maschinelles Lernen. Damit ist es nicht nur für das B2C-, sondern auch für das B2B-Segment geeignet und bietet einen nahtlosen Ersatz für das Produkt von OpenAI, ohne dass die Anwendungslogik geändert werden muss.
Eine der am meisten nachgefragten Funktionen ist die erweiterte Kontextlänge. Standardmäßig unterstützt es 256k Token, kann aber mit dem Mechanismus YaRN (Yet another RoPe extensioN) auf 1M erhöht werden. Moderne LLMs werden in der Regel auf kurzen Datensätzen (2k-8k Token) trainiert, und große Kontextlängen können dazu führen, dass sie den Überblick über frühere Inhalte verlieren.
YaRN ist ein eleganter "Trick", der dem Modell vorgaukelt, dass es mit seinen üblichen kurzen Sequenzen arbeitet, während es in Wirklichkeit viel längere Sequenzen verarbeitet. Die Schlüsselidee besteht darin, den Positionsraum zu "strecken" oder zu "dehnen", während die mathematische Struktur, die das Modell erwartet, erhalten bleibt. Dies ermöglicht die effektive Verarbeitung von Sequenzen mit einer Länge von Zehntausenden von Token, ohne dass eine Umschulung oder ein zusätzlicher Speicher erforderlich ist, wie es bei herkömmlichen Kontexterweiterungsmethoden der Fall ist.
Herunterladen und Ausführen der Inferenz
Vergewissern Sie sich, dass Sie zuvor CUDA® installiert haben. Verwenden Sie dazu entweder die offiziellen Anweisungen von NVIDIA® oder die Anleitung CUDA® Toolkit unter Linux installieren. Prüfen Sie, ob der erforderliche Compiler vorhanden ist:
nvcc --versionErwartete Ausgabe:
nvcc: NVIDIA (R) Cuda compiler driver Copyright (c) 2005-2024 NVIDIA Corporation Built on Tue_Feb_27_16:19:38_PST_2024 Cuda compilation tools, release 12.4, V12.4.99 Build cuda_12.4.r12.4/compiler.33961263_0
Wenn Sie erhalten:
Command 'nvcc' not found, but can be installed with: sudo apt install nvidia-cuda-toolkit
erhalten, müssen Sie die CUDA® Binärdateien zum $PATH Ihres Systems hinzufügen.
export PATH=/usr/local/cuda-12.4/bin:$PATHexport LD_LIBRARY_PATH=/usr/local/cuda-12.4/lib64:$LD_LIBRARY_PATHDies ist eine vorübergehende Lösung. Für eine dauerhafte Lösung editieren Sie ~/.bashrc und fügen Sie die gleichen zwei Zeilen am Ende hinzu.
Bereiten Sie nun Ihr System für die Verwaltung virtueller Umgebungen vor. Sie können Pythons eingebautes venv oder das fortschrittlichere Miniforge verwenden. Angenommen, Miniforge ist installiert:
conda create -n venv python=3.10conda activate venvInstallieren Sie PyTorch mit CUDA® Unterstützung passend zu Ihrem System:
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu124Installieren Sie dann die wesentlichen Bibliotheken:
- Transformers - Die Hauptmodellbibliothek von Hugging Face
- Accelerate - ermöglicht Multi-GPU-Inferenz
- HuggingFace Hub - zum Herunter-/Hochladen von Modellen und Datensätzen
- Safetensors - sicheres Modellgewichtsformat
- vLLM - empfohlene Inferenzbibliothek für Qwen
pip install transformers accelerate huggingface_hub safetensors vllmLaden Sie das Modell herunter:
hf download Qwen/Qwen3-Coder-30B-A3B-Instruct --local-dir ./Qwen3-30BInferenz mit Tensor-Parallelität durchführen (Aufteilung der Schichttensoren auf GPUs, z. B. 8):
python -m vllm.entrypoints.openai.api_server \
--model /home/usergpu/Qwen3-30B \
--tensor-parallel-size 8 \
--gpu-memory-utilization 0.9 \
--dtype auto \
--host 0.0.0.0 \
--port 8000Dadurch wird der vLLM OpenAI API Server gestartet.
Testen und Integration
cURL
Installieren Sie jq für das Pretty-Printing von JSON:
sudo apt -y install jqTesten Sie den Server:
curl -s http://127.0.0.1:8000/v1/chat/completions -H "Content-Type: application/json" -d '{
"model": "/home/usergpu/Qwen3-30B",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello! What can you do?"}
],
"max_tokens": 180
}' | jq -r '.choices[0].message.content'VSCode
Um Visual Studio Code zu integrieren, installieren Sie die Erweiterung Continue und fügen Sie sie zu config.yaml hinzu:
- name: Qwen3-Coder 30B
provider: openai
apiBase: http://[server_IP_address]:8000/v1
apiKey: none
model: /home/usergpu/Qwen3-30B
roles:
- chat
- edit
- apply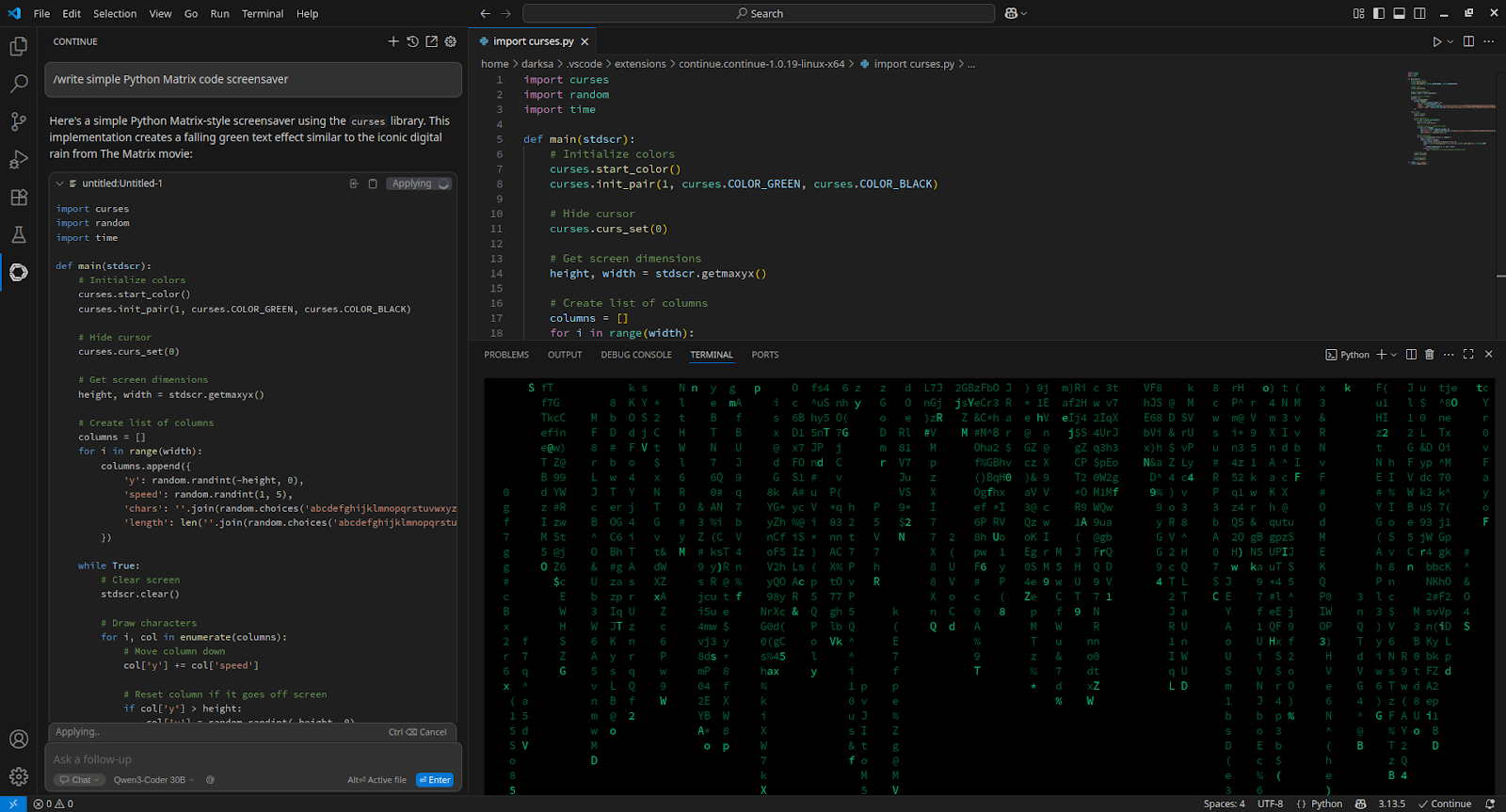
Qwen-Agent
Für eine GUI-basierte Einrichtung mit Qwen-Agent (einschließlich RAG, MCP und Code-Interpreter):
pip install -U "qwen-agent[gui,rag,code_interpreter,mcp]"Öffnen Sie den nano-Editor:
nano script.pyBeispiel Python-Skript zum Starten von Qwen-Agent mit einer Gradio WebUI:
from qwen_agent.agents import Assistant
from qwen_agent.gui import WebUI
llm_cfg = {
'model': '/home/usergpu/Qwen3-30B',
'model_server': 'http://localhost:8000/v1',
'api_key': 'EMPTY',
'generate_cfg': {'top_p': 0.8},
}
tools = ['code_interpreter']
bot = Assistant(
llm=llm_cfg,
system_message="You are a helpful coding assistant.",
function_list=tools
)
WebUI(bot).run()Führen Sie das Skript aus:
python script.pyDer Server wird verfügbar sein unter: http://127.0.0.1:7860
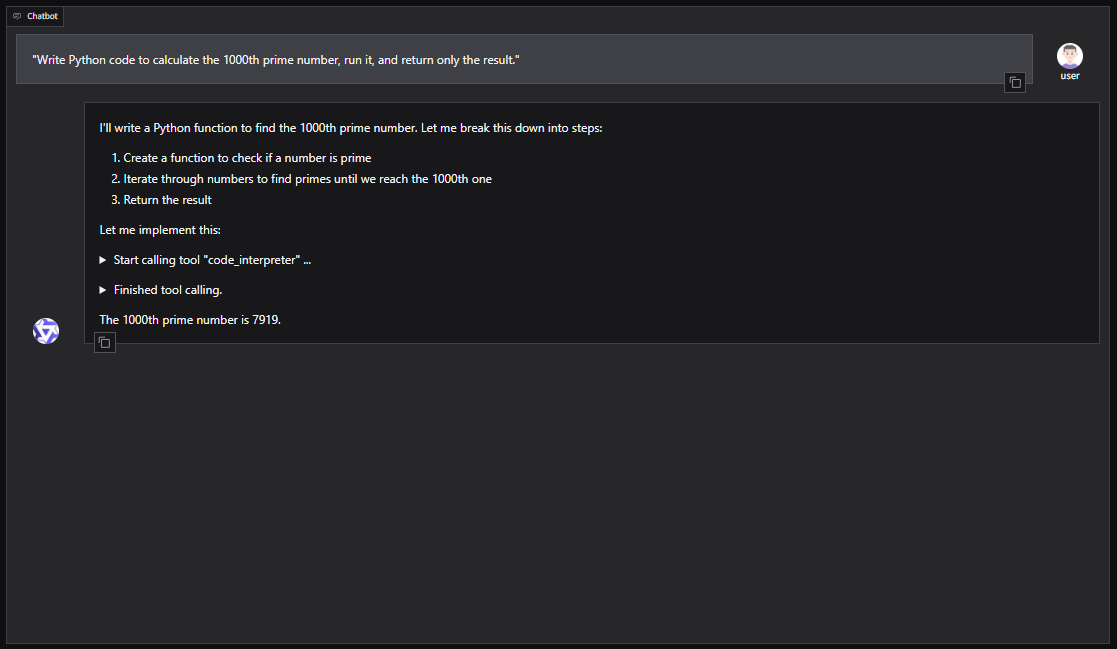
Sie können Qwen3-Coder auch in Agenten-Frameworks wie CrewAI integrieren, um komplexe Aufgaben mit Toolsets wie Websuche oder Vektordatenbank-Speicher zu automatisieren.
Siehe auch:
Aktualisiert: 04.01.2026
Veröffentlicht: 12.08.2025




