





Triton™ Inference Server

Die Anforderungen der Unternehmen mögen unterschiedlich sein, aber sie alle haben ein gemeinsames Grundprinzip: Die Systeme müssen schnell arbeiten und die höchstmögliche Qualität liefern. Bei der Inferenz neuronaler Netze ist die effiziente Nutzung von Rechenressourcen entscheidend. Jede unzureichende Nutzung der GPU oder Leerlaufzeit führt direkt zu finanziellen Verlusten.
Nehmen wir als Beispiel einen Marktplatz. Auf diesen Plattformen werden zahlreiche Produkte angeboten, die jeweils mehrere Attribute aufweisen: Textbeschreibungen, technische Spezifikationen, Kategorien und Multimedia-Inhalte wie Fotos und Videos. Alle Inhalte müssen moderiert werden, um faire Bedingungen für Verkäufer zu gewährleisten und zu verhindern, dass verbotene Waren oder illegale Inhalte auf der Plattform erscheinen.
Eine manuelle Moderation ist zwar möglich, aber sie ist langsam und ineffizient. Im heutigen Wettbewerbsumfeld müssen Verkäufer ihre Produktpalette schnell erweitern: Je schneller die Artikel auf dem Marktplatz erscheinen, desto größer sind die Chancen, entdeckt und gekauft zu werden. Die manuelle Moderation ist außerdem kostspielig und anfällig für menschliche Fehler, die dazu führen können, dass ungeeignete Inhalte durchgelassen werden.
Die automatische Moderation mit Hilfe speziell trainierter neuronaler Netze bietet eine Lösung. Dieser Ansatz bringt mehrere Vorteile mit sich: Er senkt die Moderationskosten erheblich und verbessert in der Regel die Qualität. Neuronale Netze verarbeiten Inhalte viel schneller als Menschen, so dass die Verkäufer die Moderationsphase schneller durchlaufen können, insbesondere bei großen Produktmengen.
Der Ansatz hat aber auch seine Tücken. Die Implementierung einer automatisierten Moderation erfordert die Entwicklung und das Training von neuronalen Netzwerkmodellen, was sowohl qualifiziertes Personal als auch umfangreiche Computerressourcen erfordert. Die Vorteile werden jedoch schnell nach der ersten Implementierung deutlich. Die Einführung einer automatischen Modellbereitstellung kann den laufenden Betrieb erheblich rationalisieren.
Schlussfolgerung
Nehmen wir an, wir haben die Verfahren des maschinellen Lernens herausgefunden. Der nächste Schritt ist die Festlegung, wie die Modellinferenz auf einem gemieteten Server ausgeführt werden soll. Für ein einzelnes Modell wählen Sie in der Regel ein Tool, das gut mit dem spezifischen Framework funktioniert, auf dem es erstellt wurde. Bei mehreren Modellen, die in verschiedenen Frameworks erstellt wurden, haben Sie jedoch zwei Möglichkeiten.
Sie können entweder alle Modelle in ein einziges Format konvertieren oder ein Tool wählen, das mehrere Frameworks unterstützt. Der Triton™ Inference Server eignet sich perfekt für den zweiten Ansatz. Er unterstützt die folgenden Backends:
- TensorRT™
- TensorRT-LLM
- vLLM
- Python
- PyTorch (LibTorch)
- ONNX Laufzeit
- Tensorflow
- FIL
- DALI
Zusätzlich können Sie jede Anwendung als Backend verwenden. Wenn Sie zum Beispiel Post-Processing mit einer C/C++ Anwendung benötigen, können Sie diese nahtlos integrieren.
Skalierung
Der Triton™ Inference Server verwaltet die Rechenressourcen auf einem einzigen Server effizient, indem er mehrere Modelle gleichzeitig ausführt und die Arbeitslast auf die GPUs verteilt.
Die Installation erfolgt über einen Docker-Container. DevOps-Ingenieure können die GPU-Zuweisung beim Start steuern und entscheiden, ob sie alle GPUs nutzen oder deren Anzahl begrenzen möchten. Die Software ermöglicht zwar keine direkte horizontale Skalierung, aber Sie können zu diesem Zweck herkömmliche Load Balancer wie HAproxy verwenden oder Anwendungen in einem Kubernetes-Cluster bereitstellen.
Vorbereiten des Systems
Um Triton™ auf einem LeaderGPU-Server unter Ubuntu 22.04 einzurichten, aktualisieren Sie das System zunächst mit diesem Befehl:
sudo apt update && sudo apt -y upgradeInstallieren Sie zunächst die Nvidia-Treiber mit Hilfe des Auto-Installer-Skripts:
sudo ubuntu-drivers autoinstallStarten Sie den Server neu, um die Änderungen zu übernehmen:
sudo shutdown -r nowSobald der Server wieder online ist, installieren Sie Docker mit dem folgenden Installationsskript:
curl -sSL https://get.docker.com/ | shDa Docker standardmäßig keine GPUs an Container weitergeben kann, benötigen Sie das NVIDIA® Container Toolkit. Fügen Sie das Nvidia-Repository hinzu, indem Sie seinen GPG-Schlüssel herunterladen und registrieren:
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.listAktualisieren Sie den Paket-Cache und installieren Sie das Toolkit:
sudo apt update && sudo apt -y install nvidia-container-toolkitStarten Sie Docker neu, um die neuen Funktionen zu aktivieren:
sudo systemctl restart dockerDas Betriebssystem ist nun einsatzbereit.
Installation von Triton™ Inference Server
Laden wir das Projekt-Repository herunter:
git clone https://github.com/triton-inference-server/serverDieses Repository enthält vorkonfigurierte Beispiele für neuronale Netze und ein Modell-Download-Skript. Navigieren Sie zum Verzeichnis examples:
cd server/docs/examplesLaden Sie die Modelle herunter, indem Sie das folgende Skript ausführen, das sie unter ~/server/docs/examples/model_repository speichert:
./fetch_models.shDie Architektur des Triton™ Inference Servers erfordert, dass die Modelle separat gespeichert werden. Sie können sie entweder lokal in einem beliebigen Serververzeichnis oder auf einem Netzwerkspeicher ablegen. Wenn Sie den Server starten, müssen Sie dieses Verzeichnis in den Container unter dem Einhängepunkt /models einhängen. Dies dient als Repository für alle Modellversionen.
Starten Sie den Container mit folgendem Befehl
sudo docker run --gpus=all --rm -p8000:8000 -p8001:8001 -p8002:8002 -v ~/server/docs/examples/model_repository:/models nvcr.io/nvidia/tritonserver:25.01-py3 tritonserver --model-repository=/modelsDie einzelnen Parameter sind wie folgt zu verstehen:
- --gpus=all legt fest, dass alle verfügbaren GPUs im Server verwendet werden;
- --rm zerstört den Container, nachdem der Prozess abgeschlossen oder angehalten wurde;
- -p8000:8000 leitet Port 8000 weiter, um HTTP-Anfragen zu empfangen;
- -p8001:8001 leitet Port 8001 weiter, um gRPC-Anfragen zu empfangen;
- -p8002:8002 leitet Port 8002 weiter, um Metriken anzufordern;
- -v ~/server/docs/examples/model_repository:/models leitet das Verzeichnis mit den Modellen weiter;
- nvcr.io/nvidia/tritonserver:25.01-py3 Adresse des Containers aus dem NGC-Katalog;
- tritonserver --model-repository=/models startet den Triton™ Inference Server mit dem Speicherort des Models Repository unter /models.
Die Befehlsausgabe zeigt alle verfügbaren Modelle im Repository an, die alle bereit sind, Anfragen zu akzeptieren:
+----------------------+---------+--------+ | Model | Version | Status | +----------------------+---------+--------+ | densenet_onnx | 1 | READY | | inception_graphdef | 1 | READY | | simple | 1 | READY | | simple_dyna_sequence | 1 | READY | | simple_identity | 1 | READY | | simple_int8 | 1 | READY | | simple_sequence | 1 | READY | | simple_string | 1 | READY | +----------------------+---------+--------+
Die drei Dienste wurden erfolgreich auf den Ports 8000, 8001 und 8002 gestartet:
I0217 08:00:34.930188 1 grpc_server.cc:2466] Started GRPCInferenceService at 0.0.0.0:8001 I0217 08:00:34.930393 1 http_server.cc:4636] Started HTTPService at 0.0.0.0:8000 I0217 08:00:34.972340 1 http_server.cc:320] Started Metrics Service at 0.0.0.0:8002
Mit dem Dienstprogramm nvtop können wir überprüfen, ob alle GPUs bereit sind, die Last aufzunehmen:
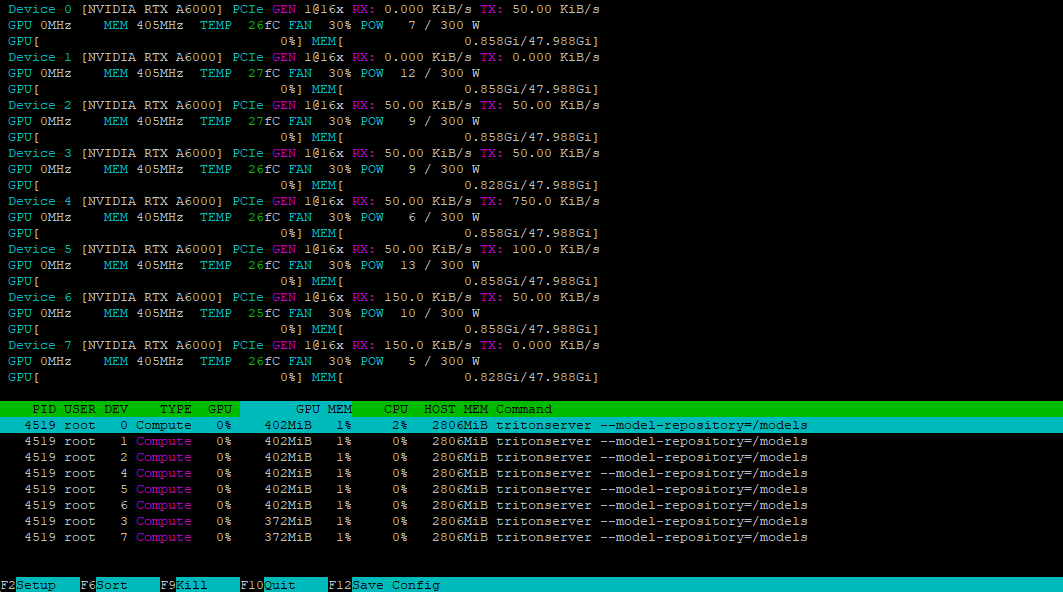
Installieren des Clients
Um auf unseren Server zuzugreifen, müssen wir eine entsprechende Anfrage mit dem im SDK enthaltenen Client erstellen. Wir können dieses SDK als Docker-Container herunterladen:
sudo docker pull nvcr.io/nvidia/tritonserver:25.01-py3-sdkStarten Sie den Container im interaktiven Modus, um auf die Konsole zuzugreifen:
sudo docker run -it --gpus=all --rm --net=host nvcr.io/nvidia/tritonserver:25.01-py3-sdkTesten wir dies mit dem DenseNet-Modell im ONNX-Format, indem wir die INCEPTION-Methode zur Vorverarbeitung und Analyse von Bildern verwenden mug.jpg:
/workspace/install/bin/image_client -m densenet_onnx -c 3 -s INCEPTION /workspace/images/mug.jpgDer Client kontaktiert den Server, der einen Stapel erstellt und ihn mit den verfügbaren GPUs des Containers verarbeitet. Hier ist die Ausgabe:
Request 0, batch size 1
Image '/workspace/images/mug.jpg':
15.349562 (504) = COFFEE MUG
13.227461 (968) = CUP
10.424891 (505) = COFFEEPOTVorbereiten des Repositorys
Damit Triton™ die Modelle korrekt verwalten kann, müssen Sie das Repository auf eine bestimmte Weise vorbereiten. Hier ist die Verzeichnisstruktur:
model_repository/
└── your_model/
├── config.pbtxt
└── 1/
└── model.*
Jedes Modell benötigt ein eigenes Verzeichnis, das eine config.pbtxt Konfigurationsdatei mit der Beschreibung des Modells enthält. Hier ist ein Beispiel:
name: "Test"
platform: "pytorch_libtorch"
max_batch_size: 8
input [
{
name: "INPUT_0"
data_type: TYPE_FP32
dims: [ 3, 224, 224 ]
}
]
output [
{
name: "OUTPUT_0"
data_type: TYPE_FP32
dims: [ 1000 ]
}
]In diesem Beispiel wird ein Modell namens Test auf dem PyTorch-Backend ausgeführt. Der Parameter max_batch_size legt die maximale Anzahl von Elementen fest, die gleichzeitig verarbeitet werden können, um einen effizienten Lastausgleich zwischen den Ressourcen zu ermöglichen. Wenn dieser Wert auf Null gesetzt wird, wird die Stapelverarbeitung deaktiviert, so dass das Modell die Anfragen sequentiell verarbeitet.
Das Modell akzeptiert eine Eingabe und erzeugt eine Ausgabe, die beide den Zahlentyp FP32 verwenden. Die Parameter müssen genau mit den Anforderungen des Modells übereinstimmen. Für die Bildverarbeitung ist eine typische Dimensionsangabe dims: [ 3, 224, 224 ], wobei:
- 3 - Anzahl der Farbkanäle (RGB);
- 224 - Bildhöhe in Pixeln;
- 224 - Bildbreite in Pixeln.
Die Ausgabe dims: [ 1000 ] stellt einen eindimensionalen Vektor mit 1000 Elementen dar, der sich für Bildklassifizierungsaufgaben eignet. Um die richtige Dimensionalität für Ihr Modell zu bestimmen, konsultieren Sie die Dokumentation des Modells. Wenn die Konfigurationsdatei unvollständig ist, versucht Triton™, die fehlenden Parameter automatisch zu generieren.
Starten eines benutzerdefinierten Modells
Starten wir die Inferenz des destillierten DeepSeek-R1-Modells, das wir zuvor besprochen haben. Zunächst erstellen wir die erforderliche Verzeichnisstruktur:
mkdir ~/model_repository && mkdir ~/model_repository/deepseek && mkdir ~/model_repository/deepseek/1Navigieren Sie zum Modellverzeichnis:
cd ~/model_repository/deepseekErstellen Sie eine Konfigurationsdatei config.pbtxt:
nano config.pbtxtFügen Sie das Folgende ein:
# Copyright 2023, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
#
# Redistribution and use in source and binary forms, with or without
# modification, are permitted provided that the following conditions
# are met:
# * Redistributions of source code must retain the above copyright
# notice, this list of conditions and the following disclaimer.
# * Redistributions in binary form must reproduce the above copyright
# notice, this list of conditions and the following disclaimer in the
# documentation and/or other materials provided with the distribution.
# * Neither the name of NVIDIA CORPORATION nor the names of its
# contributors may be used to endorse or promote products derived
# from this software without specific prior written permission.
#
# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS ``AS IS'' AND ANY
# EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
# IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR
# PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR
# CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL,
# EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO,
# PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR
# PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY
# OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
# (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
# OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
# Note: You do not need to change any fields in this configuration.
backend: "vllm"
# The usage of device is deferred to the vLLM engine
instance_group [
{
count: 1
kind: KIND_MODEL
}
]Speichern Sie die Datei, indem Sie Ctrl + O drücken, dann den Editor mit Ctrl + X. Wechseln Sie in das Verzeichnis 1:
cd 1Erstellen Sie eine Modellkonfigurationsdatei model.json mit den folgenden Parametern:
{
"model":"deepseek-ai/DeepSeek-R1-Distill-Llama-8B",
"disable_log_requests": true,
"gpu_memory_utilization": 0.9,
"enforce_eager": true
}Beachten Sie, dass der Wert gpu_memory_utilization je nach GPU variiert und experimentell ermittelt werden sollte. Für diese Anleitung verwenden wir 0.9. Ihre Verzeichnisstruktur innerhalb von ~/model_repository sollte nun wie folgt aussehen:
└── deepseek
├── 1
│ └── model.json
└── config.pbtxt
Setzen Sie der Einfachheit halber die Variable LOCAL_MODEL_REPOSITORY:
LOCAL_MODEL_REPOSITORY=~/model_repository/Starten Sie den Inferenzserver mit diesem Befehl:
sudo docker run --rm -it --net host --shm-size=2g --ulimit memlock=-1 --ulimit stack=67108864 --gpus all -v $LOCAL_MODEL_REPOSITORY:/opt/tritonserver/model_repository nvcr.io/nvidia/tritonserver:25.01-vllm-python-py3 tritonserver --model-repository=model_repository/Die Bedeutung der einzelnen Parameter ist wie folgt:
- --rm Entfernt den Container nach dem Stoppen automatisch;
- -it führt den Container im interaktiven Modus mit Terminalausgabe aus;
- --net Host verwendet den Netzwerkstack des Hosts anstelle der Container-Isolation;
- --shm-size=2g setzt den gemeinsamen Speicher auf 2 GB;
- --ulimit memlock=-1 hebt die Begrenzung der Speichersperre auf;
- --ulimit stack=67108864 setzt die Stack-Größe auf 64 MB;
- --gpus all ermöglicht den Zugriff auf alle Server-GPUs;
- -v $LOCAL_MODEL_REPOSITORY:/opt/tritonserver/model_repository hängt das lokale Modellverzeichnis in den Container ein;
- nvcr.io/nvidia/tritonserver:25.01-vllm-python-py3 spezifiziert den Container mit vLLM-Backend-Unterstützung;
- tritonserver --model-repository=model_repository/ startet den Triton™ Inference Server mit dem Speicherort des Modell-Repository unter model_repository.
Testen Sie den Server, indem Sie eine Anfrage mit curl senden, wobei Sie eine einfache Eingabeaufforderung und ein Antwortlimit von 4096 Token verwenden:
curl -X POST localhost:8000/v2/models/deepseek/generate -d '{"text_input": "Tell me about the Netherlands?", "max_tokens": 4096}'Der Server empfängt und verarbeitet die Anfrage erfolgreich.
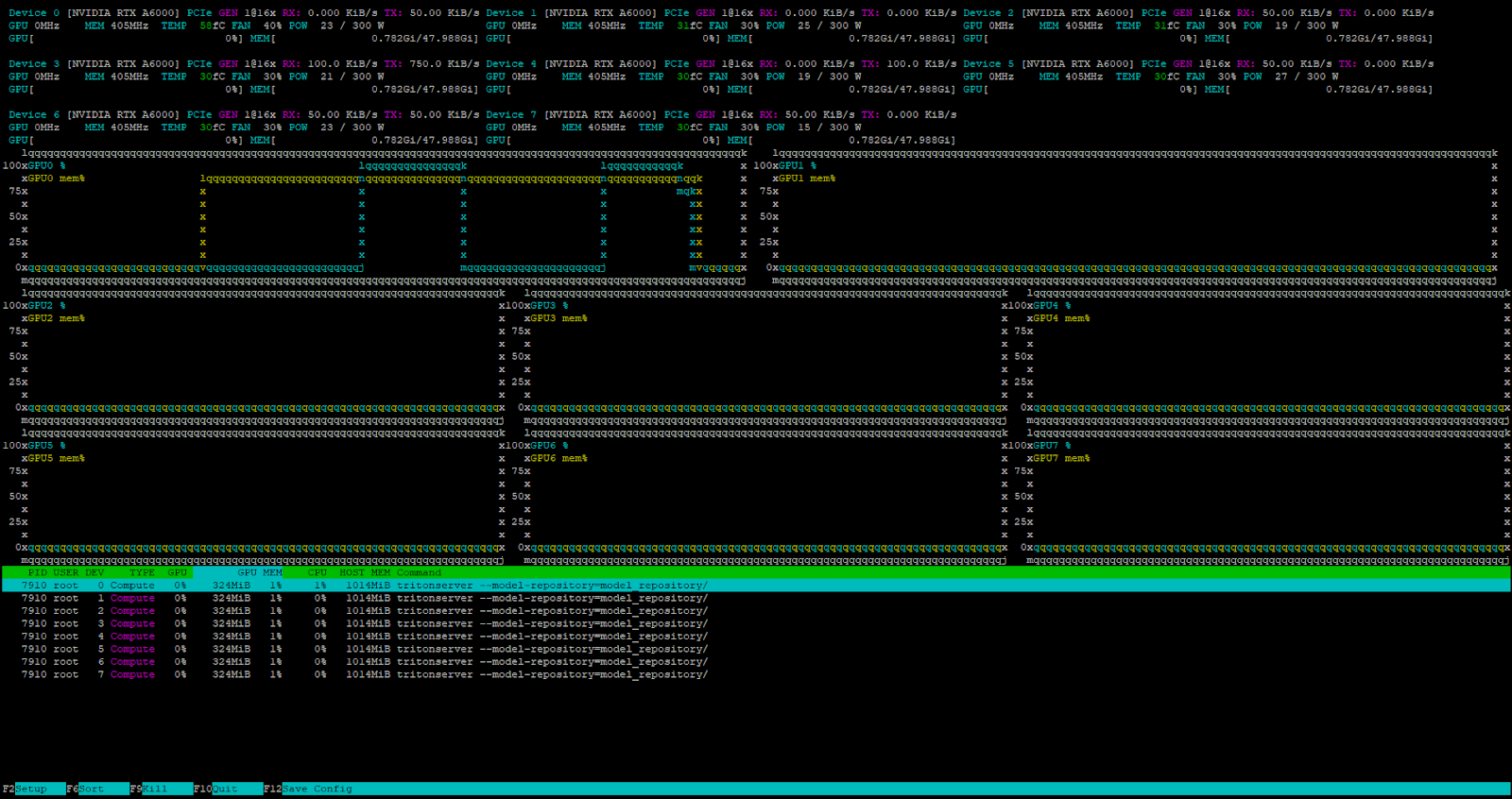
Der interne Triton-Aufgabenplaner bearbeitet alle eingehenden Anfragen, wenn der Server unter Last steht.
Fazit
Der Triton™ Inference Server eignet sich hervorragend für den Einsatz von Machine-Learning-Modellen in der Produktion, indem er die Anfragen effizient auf die verfügbaren GPUs verteilt. Dies maximiert die Nutzung der gemieteten Serverressourcen und reduziert die Kosten für die Recheninfrastruktur. Die Software arbeitet mit verschiedenen Backends, einschließlich vLLM für große Sprachmodelle.
Da sie als Docker-Container installiert wird, können Sie sie problemlos in jede moderne CI/CD-Pipeline integrieren. Probieren Sie es selbst aus und mieten Sie einen Server von LeaderGPU.
Aktualisiert: 04.01.2026
Veröffentlicht: 26.02.2025




