





DeepSeek-R1: Zukunft der LLMs

Generative neuronale Netze haben sich zwar rasant entwickelt, doch in den letzten Jahren waren ihre Fortschritte relativ konstant. Dies änderte sich mit DeepSeek, einem chinesischen neuronalen Netzwerk, das nicht nur die Börse beeinflusste, sondern auch die Aufmerksamkeit von Entwicklern und Forschern weltweit auf sich zog. Im Gegensatz zu anderen Großprojekten wurde der Code von DeepSeek unter der freizügigen MIT-Lizenz veröffentlicht. Dieser Schritt in Richtung Open Source wurde von der Community gelobt, die eifrig begann, die Fähigkeiten des neuen Modells zu erforschen.
Der beeindruckendste Aspekt war, dass das Training dieses neuen neuronalen Netzwerks Berichten zufolge 20 Mal weniger kostete als das von Konkurrenten, die eine ähnliche Qualität bieten. Das Modell benötigte nur 55 Tage und 5,6 Millionen Dollar für das Training. Als DeepSeek veröffentlicht wurde, löste es einen der größten Tageseinbrüche in der Geschichte des US-Aktienmarktes aus. Obwohl sich die Märkte schließlich stabilisierten, waren die Auswirkungen erheblich.
In diesem Artikel wird untersucht, wie genau die Schlagzeilen in den Medien die Realität widerspiegeln, und es wird erforscht, welche LeaderGPU-Konfigurationen geeignet sind, um dieses neuronale Netzwerk selbst zu installieren.
Architektonische Merkmale
DeepSeek hat einen Weg der maximalen Optimierung gewählt, was angesichts der Exportbeschränkungen Chinas in die USA nicht überrascht. Diese Beschränkungen hindern das Land daran, offiziell die fortschrittlichsten GPU-Modelle für die KI-Entwicklung zu nutzen.
Das Modell nutzt die Multi Token Prediction (MTP)-Technologie, die mehrere Token in einem einzigen Inferenzschritt vorhersagt statt nur eines. Dies funktioniert durch parallele Token-Dekodierung in Kombination mit speziellen maskierten Schichten, die die Autoregressivität aufrechterhalten.
MTP-Tests haben bemerkenswerte Ergebnisse gezeigt, die die Generierungsgeschwindigkeit im Vergleich zu herkömmlichen Methoden um das 2 bis 4-fache erhöhen. Die hervorragende Skalierbarkeit der Technologie macht sie für aktuelle und zukünftige Anwendungen der natürlichen Sprachverarbeitung wertvoll.
Das Multi-Head Latent Attention (MLA) Modell verfügt über einen erweiterten Aufmerksamkeitsmechanismus. Während das Modell lange Ketten von Schlussfolgerungen aufbaut, behält es in jeder Phase die Aufmerksamkeit auf den Kontext. Diese Erweiterung verbessert den Umgang mit abstrakten Konzepten und Textabhängigkeiten.
Das Hauptmerkmal von MLA ist die Fähigkeit, die Aufmerksamkeitsgewichtung auf verschiedenen Abstraktionsebenen dynamisch anzupassen. Bei der Verarbeitung komplexer Abfragen untersucht MLA die Daten aus mehreren Perspektiven: Wortbedeutungen, Satzstrukturen und Gesamtkontext. Diese Perspektiven bilden verschiedene Ebenen, die die endgültige Ausgabe beeinflussen. Um die Übersichtlichkeit zu wahren, gleicht MLA die Auswirkungen der einzelnen Ebenen sorgfältig aus und konzentriert sich dabei auf die Hauptaufgabe.
Die Entwickler von DeepSeek haben die Mixture of Experts (MoE) Technologie in das Modell integriert. Es enthält 256 vortrainierte neuronale Expertennetzwerke, die jeweils auf unterschiedliche Aufgaben spezialisiert sind. Das System aktiviert 8 dieser Netze für jede Token-Eingabe und ermöglicht so eine effiziente Datenverarbeitung ohne Erhöhung der Rechenkosten.
Im vollständigen Modell mit 671b Parametern werden nur 37b für jedes Token aktiviert. Das Modell wählt auf intelligente Weise die relevantesten Parameter für die Verarbeitung jedes eingehenden Tokens aus. Diese effiziente Optimierung spart Rechenressourcen bei gleichbleibend hoher Leistung.
Ein entscheidendes Merkmal jedes Chatbots mit neuronalem Netzwerk ist die Länge des Kontextfensters. Llama 2 hat ein Kontextlimit von 4.096 Token, GPT-3.5 kann 16.284 Token verarbeiten, während GPT-4 und DeepSeek bis zu 128.000 Token verarbeiten können (etwa 100.000 Wörter, was 300 Seiten maschinengeschriebenen Textes entspricht).
R - steht für Reasoning
DeepSeek-R1 verfügt über einen Reasoning-Mechanismus ähnlich dem von OpenAI o1, der es ihm ermöglicht, komplexe Aufgaben effizienter und genauer zu bearbeiten. Anstatt sofortige Antworten zu geben, erweitert das Modell den Kontext, indem es schrittweise Schlussfolgerungen in kleinen Absätzen generiert. Dieser Ansatz verbessert die Fähigkeit des neuronalen Netzwerks, komplexe Datenbeziehungen zu erkennen, was zu umfassenderen und präziseren Antworten führt.
Wenn DeepSeek mit einer komplexen Aufgabe konfrontiert wird, nutzt es seinen Argumentationsmechanismus, um das Problem in einzelne Komponenten zu zerlegen und jede einzelne zu analysieren. Das Modell fasst diese Erkenntnisse dann zusammen, um eine Antwort für den Benutzer zu generieren. Obwohl dies ein idealer Ansatz für neuronale Netze zu sein scheint, ist er mit erheblichen Herausforderungen verbunden.
Alle modernen LLMs haben eine besorgniserregende Eigenschaft gemeinsam - künstliche Halluzinationen. Wenn eine Frage gestellt wird, die es nicht beantworten kann, kann es passieren, dass das Modell, anstatt seine Grenzen anzuerkennen, fiktive Antworten erzeugt, die durch erfundene Fakten gestützt werden.
Bei der Anwendung auf ein logisch denkendes neuronales Netz könnten diese Halluzinationen den Denkprozess beeinträchtigen, da die Schlussfolgerungen eher auf fiktiven als auf faktischen Informationen beruhen. Dies könnte zu falschen Schlussfolgerungen führen - eine Herausforderung, der sich Forscher und Entwickler neuronaler Netze in Zukunft stellen müssen.
VRAM-Verbrauch
Untersuchen wir, wie DeepSeek R1 auf einem dedizierten Server ausgeführt und getestet werden kann, und konzentrieren wir uns dabei auf die Anforderungen an den GPU-Videospeicher.
| Modell | VRAM (Mb) | Modellgröße (Gb) |
|---|---|---|
| deepseek-r1:1.5b | 1,952 | 1.1 |
| deepseek-r1:7b | 5,604 | 4.7 |
| Tiefensuche-r1:8b | 6,482 | 4.9 |
| Tiefensuche-r1:14b | 10,880 | 9 |
| Tiefensuche-r1:32b | 21,758 | 20 |
| Tiefensuche-r1:70b | 39,284 | 43 |
| Tiefensuche-r1:671b | 470,091 | 404 |
Die ersten drei Optionen (1.5b, 7b, 8b) sind Basismodelle, die die meisten Aufgaben effizient erledigen können. Diese Modelle laufen reibungslos auf jeder Consumer-GPU mit 6-8 GB Videospeicher. Die mittleren Versionen (14b und 32b) sind ideal für professionelle Aufgaben, benötigen aber mehr VRAM. Die größten Modelle (70b und 671b) erfordern spezielle Grafikprozessoren und werden vor allem in der Forschung und für industrielle Anwendungen eingesetzt.
Server-Auswahl
Um Ihnen die Auswahl eines Servers für DeepSeek-Inferenz zu erleichtern, finden Sie hier die idealen LeaderGPU-Konfigurationen für jede Modellgruppe:
1,5b / 7b / 8b / 14b / 32b / 70b
Für diese Gruppe ist jeder Server mit den folgenden GPU-Typen geeignet. Die meisten LeaderGPU-Server können diese neuronalen Netze ohne Probleme ausführen. Die Leistung hängt hauptsächlich von der Anzahl der CUDA-Kerne ab. Wir empfehlen Server mit mehreren GPUs, wie zum Beispiel:
671b
Nun zum schwierigsten Fall: Wie können Sie Inferenzen für ein Modell mit einer Basisgröße von 404 GB durchführen? Das bedeutet, dass etwa 470 GB Videospeicher benötigt werden. LeaderGPU bietet mehrere Konfigurationen mit den folgenden GPUs, die diese Last bewältigen können:
Beide Konfigurationen handhaben die Modelllast effizient und verteilen sie gleichmäßig auf mehrere GPUs. So sieht zum Beispiel ein Server mit 8xH100 nach dem Laden des Modells deepseek-r1:671b aus:
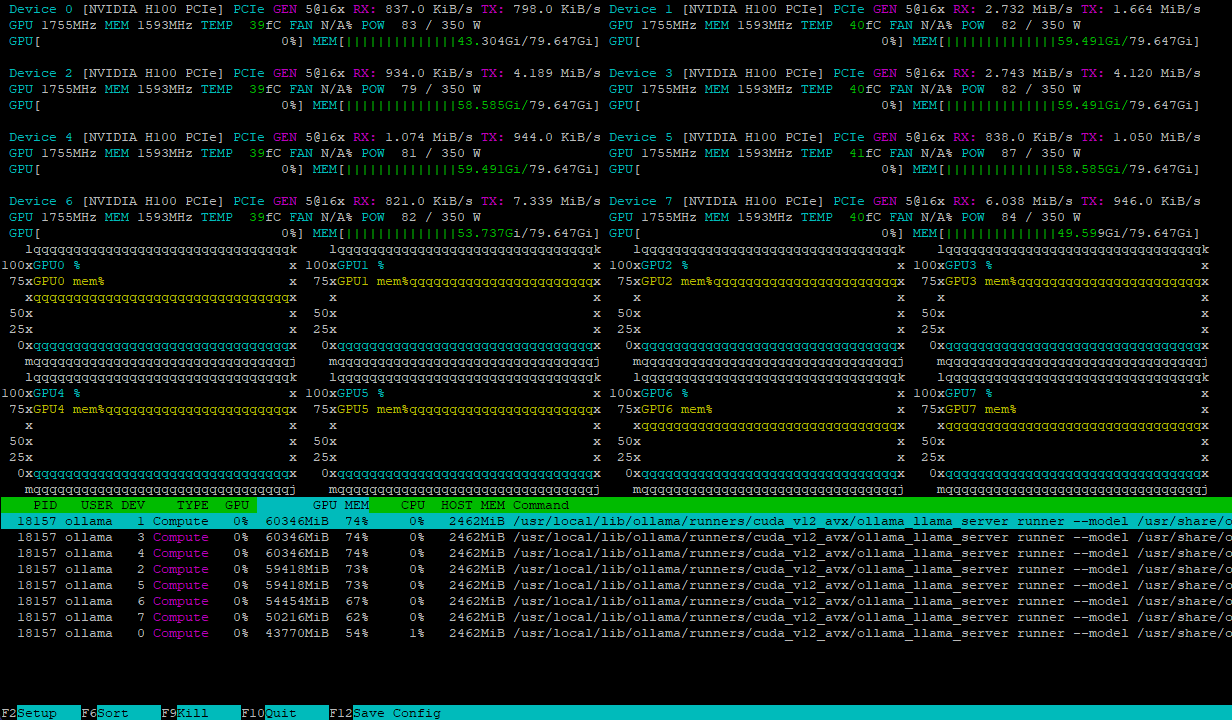
Die Rechenlast verteilt sich dynamisch auf die GPUs, während Hochgeschwindigkeits-NVLink-Verbindungen Engpässe beim Datenaustausch verhindern und so für maximale Leistung sorgen.
Schlussfolgerung
DeepSeek-R1 kombiniert viele innovative Technologien wie Multi Token Prediction, Multi-Head Latent Attention und Mixture of Experts in einem signifikanten Modell. Diese Open-Source-Software zeigt, dass LLMs mit weniger Rechenressourcen effizienter entwickelt werden können. Das Modell hat verschiedene Versionen, von kleineren 1,5b bis zu riesigen 671b, die spezielle Hardware mit mehreren parallel arbeitenden High-End-GPUs erfordern.
Wenn Sie einen Server von LeaderGPU für DeepSeek-R1-Inferenz mieten, erhalten Sie eine breite Palette von Konfigurationen, Zuverlässigkeit und Fehlertoleranz. Unser technisches Support-Team hilft Ihnen bei allen Problemen oder Fragen, während die automatische Betriebssysteminstallation die Bereitstellungszeit reduziert.
Wählen Sie Ihren LeaderGPU-Server und entdecken Sie die Möglichkeiten, die sich bei der Verwendung moderner neuronaler Netzwerkmodelle eröffnen. Wenn Sie irgendwelche Fragen haben, zögern Sie nicht, sie in unserem Chat oder per E-Mail zu stellen.
Aktualisiert: 04.01.2026
Veröffentlicht: 19.02.2025




