





AudioCraft von MetaAI: Musik nach Beschreibung erstellen

Moderne generative neuronale Netze werden immer intelligenter. Sie schreiben Geschichten, führen Gespräche mit Menschen und erstellen ultra-realistische Bilder. Jetzt können sie auch einfache Musiktitel produzieren, ohne dass dafür professionelle Künstler benötigt werden. Diese Zukunft ist heute schon Realität. Das war zu erwarten, denn musikalische Harmonien und Rhythmen beruhen auf mathematischen Prinzipien.
Meta hat sein Engagement für die Welt der Open-Source-Software unter Beweis gestellt. Sie haben drei neuronale Netzwerkmodelle veröffentlicht, die die Erstellung von Klängen und Musik aus Textbeschreibungen ermöglichen:
- MusicGen - erzeugt Musik aus Text.
- AudioGen - erzeugt Audio aus Text.
- EnCodec - Hochwertiger neuronaler Audiokompressor.
MusicGen wurde auf 20.000 Stunden Musik trainiert. Sie können es lokal über dedizierte LeaderGPU-Server als Plattform nutzen.
Standard-Installation
Aktualisieren Sie das Paket-Cache-Repository:
sudo apt update && sudo apt -y upgradeInstallieren Sie den Python-Paketmanager, pip, und die ffmpeg-Bibliotheken:
sudo apt -y install python3-pip ffmpegInstallieren Sie Torch 2.0 oder eine neuere Version mit pip:
pip install 'torch>=2.0'Mit dem folgenden Befehl werden audiocraft und alle erforderlichen Abhängigkeiten automatisch installiert:
pip install -U audiocraftLassen Sie uns eine einfache Python-Anwendung schreiben, die das große vortrainierte MusicGen-Modell mit 3,3B Parametern verwendet:
nano generate.pyfrom audiocraft.models import MusicGen
from audiocraft.data.audio import audio_write
model = MusicGen.get_pretrained("facebook/musicgen-large")
model.set_generation_params(duration=30) # generate a 30 seconds sample.
descriptions = ["rock solo"]
wav = model.generate(descriptions) # generates sample.
for idx, one_wav in enumerate(wav):
# Will save under {idx}.wav, with loudness normalization at -14 db LUFS.
audio_write(f'{idx}', one_wav.cpu(), model.sample_rate, strategy="loudness")Führen Sie die erstellte Anwendung aus:
python3 generate.pyNach ein paar Sekunden erscheint die erzeugte Datei (0.wav) im Verzeichnis.
Kaffee Vampir 3
Klonen Sie ein Projekt-Repository:
git clone https://github.com/CoffeeVampir3/audiocraft-webui.gitÖffnen Sie das geklonte Verzeichnis:
cd audiocraft-webuiFühren Sie den Befehl aus, der Ihr System vorbereitet und alle erforderlichen Pakete installiert:
pip install -r requirements.txtStarten Sie dann den Coffee Vampire 3 Server mit dem folgenden Befehl:
python3 webui.pyCoffee Vampire 3 verwendet Flask als Framework. Standardmäßig läuft es auf localhost mit Port 5000. Wenn Sie einen Fernzugriff wünschen, verwenden Sie bitte die Portweiterleitung in Ihrem SSH-Client. Ansonsten können Sie eine VPN-Verbindung zum Server organisieren.
Aber Achtung! Dies ist eine potenziell gefährliche Aktion; die Verwendung erfolgt auf eigene Gefahr:
nano webui.pyScrollen Sie bis zum Ende und ersetzen Sie socketio.run(app) durch socketio.run(app, host=’0.0.0.0’, port=5000)
Speichern Sie die Datei und starten Sie den Server mit dem obigen Befehl. Dies ermöglicht den Zugriff auf den Server aus dem öffentlichen Internet ohne jegliche Authentifizierung.
Vergessen Sie nicht disable AdBlock software, da dies den Musik-Player auf der rechten Seite der Webseite blockieren kann. Sie können beginnen, indem Sie die Eingabeaufforderung eingeben und mit der Schaltfläche Submit bestätigen:
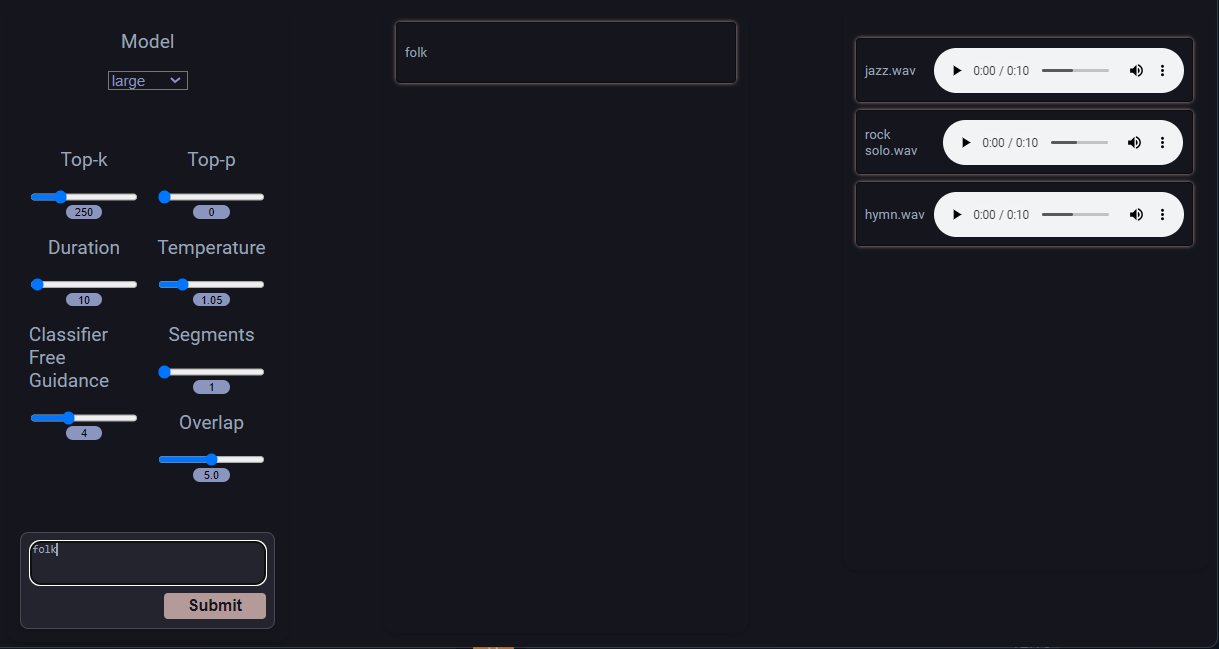
TTS Generation WebUI
Schritt 1. Treiber
Aktualisieren Sie das Paket-Cache-Repository:
sudo apt update && sudo apt -y upgradeInstallieren Sie Nvidia-Treiber mit dem automatischen Installationsprogramm oder mit unserer Anleitung Nvidia-Treiber unter Linux installieren:
sudo ubuntu-drivers autoinstallStarten Sie den Server neu:
sudo shutdown -r nowSchritt 2. Docker
Der nächste Schritt ist die Installation von Docker. Lassen Sie uns einige Pakete installieren, die dem Docker-Repository hinzugefügt werden müssen:
sudo apt -y install apt-transport-https curl gnupg-agent ca-certificates software-properties-commonLaden Sie den Docker-GPG-Schlüssel herunter und speichern Sie ihn:
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -Fügen Sie das Repository hinzu:
sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu focal stable"Installieren Sie Docker CE (Community Edition) mit CLI und die containerd Laufzeitumgebung:
sudo apt -y install docker-ce docker-ce-cli containerd.ioFügen Sie den aktuellen Benutzer zur Docker-Gruppe hinzu:
sudo usermod -aG docker $USERÜbernehmen Sie die Änderungen ohne das Ab- und Anmeldeverfahren:
newgrp dockerSchritt 3. GPU-Passthrough
Aktivieren wir NVIDIA® GPUs Passthrough in Docker. Der folgende Befehl liest die aktuelle Betriebssystemversion in die Distributionsvariable, die wir im nächsten Schritt verwenden können:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)Laden Sie den GPG-Schlüssel des Nvidia-Repositorys herunter und speichern Sie ihn:
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -Laden Sie die Liste der Nvidia-Repos herunter und speichern Sie sie zur Verwendung im Standard-APT-Paketmanager:
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.listAktualisieren Sie das Paket-Cache-Repository und installieren Sie das GPU-Passthrough-Toolkit:
sudo apt-get update && sudo apt-get install -y nvidia-container-toolkitStarten Sie den Docker-Daemon neu:
sudo systemctl restart dockerSchritt 4. WebUI
Laden Sie das Repository-Archiv herunter:
wget https://github.com/rsxdalv/tts-generation-webui/archive/refs/heads/main.zipEntpacken Sie es:
unzip main.zipÖffnen Sie das Verzeichnis des Projekts:
cd tts-generation-webui-mainBeginnen Sie mit der Erstellung des Images:
docker build -t rsxdalv/tts-generation-webui .Führen Sie den erstellten Container aus:
docker compose up -dÖffnen Sie nun http://[server_ip]:7860, geben Sie Ihre Eingabeaufforderung ein, wählen Sie das gewünschte Modell aus und klicken Sie auf die Schaltfläche Generate:
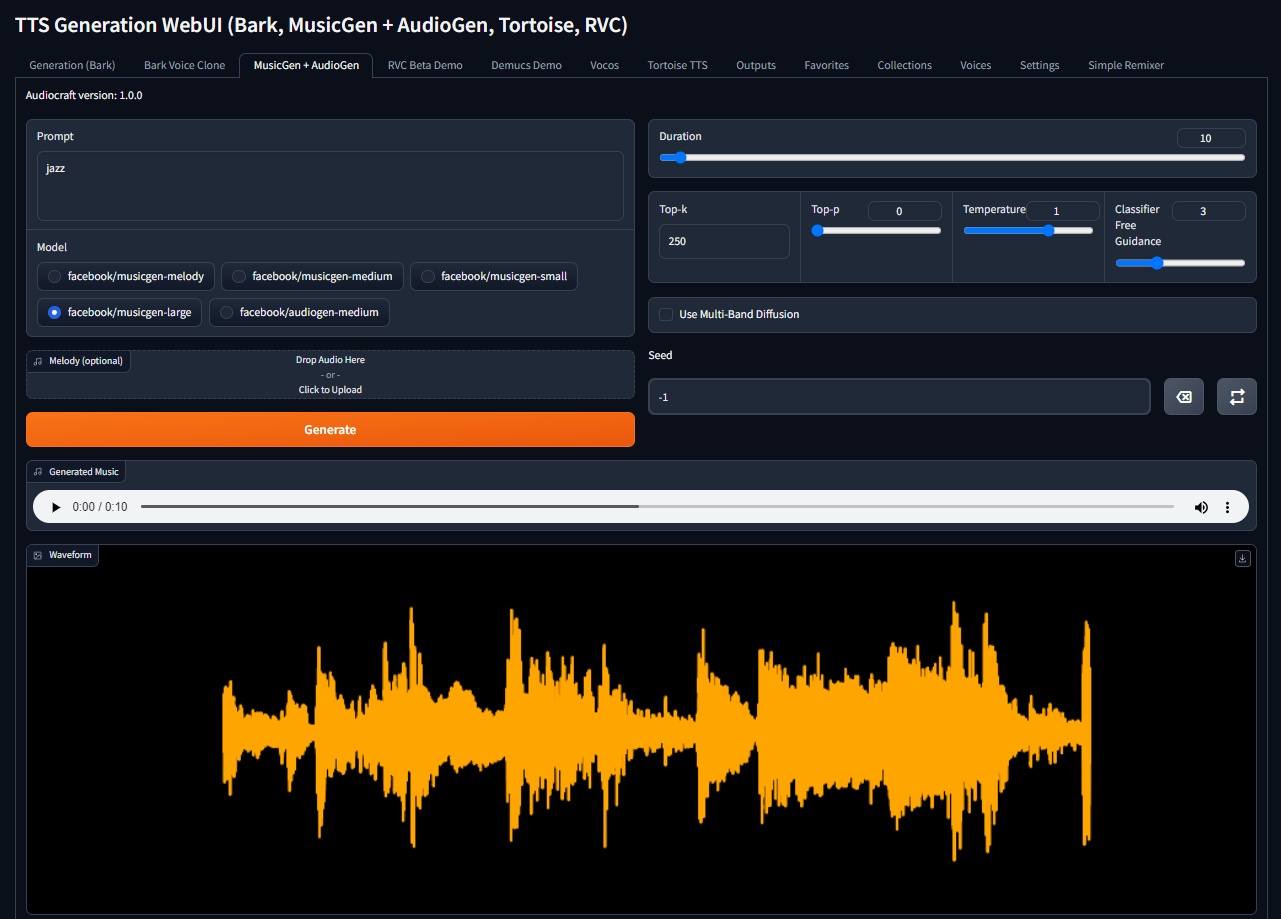
Das System lädt das ausgewählte Modell automatisch während der ersten Generation herunter. Viel Spaß!
Siehe auch:
Aktualisiert: 04.01.2026
Veröffentlicht: 22.01.2025




