





PrivateGPT: AI für Dokumente

Große Sprachmodelle haben sich in den letzten Jahren stark weiterentwickelt und sind zu effektiven Werkzeugen für viele Aufgaben geworden. Das einzige Problem bei ihrer Verwendung ist, dass die meisten Produkte, die auf diesen Modellen basieren, vorgefertigte Dienste von Drittanbietern nutzen. Diese Nutzung birgt das Potenzial, sensible Daten preiszugeben, weshalb viele Unternehmen es vermeiden, interne Dokumente in öffentliche LLM-Dienste hochzuladen.
Ein Projekt wie PrivateGPT könnte eine Lösung sein. Es ist zunächst ausschließlich für die lokale Nutzung konzipiert. Seine Stärke liegt darin, dass Sie verschiedene Dokumente als Input einreichen können, und das neuronale Netz wird sie für Sie lesen und seine eigenen Kommentare als Antwort auf Ihre Anfragen liefern. Sie können es z. B. mit umfangreichen Texten "füttern" und es auffordern, auf der Grundlage der Anfrage des Benutzers bestimmte Schlussfolgerungen zu ziehen. Auf diese Weise können Sie viel Zeit beim Korrekturlesen sparen.
Dies gilt insbesondere für Fachgebiete wie die Medizin. Ein Arzt kann zum Beispiel eine Diagnose stellen und das neuronale Netz bitten, diese auf der Grundlage der hochgeladenen Dokumente zu bestätigen. Auf diese Weise kann eine zusätzliche unabhängige Meinung eingeholt werden, wodurch die Zahl der medizinischen Fehler verringert wird. Da die Anfragen und Dokumente den Server nicht verlassen, kann man sicher sein, dass die empfangenen Daten nicht in der Öffentlichkeit erscheinen.
Heute zeigen wir Ihnen, wie Sie ein neuronales Netzwerk auf dedizierten LeaderGPU-Servern mit dem Betriebssystem Ubuntu 22.04 LTS in nur 20 Minuten einrichten können.
System vorbereiten
Beginnen Sie damit, Ihre Pakete auf die neueste Version zu aktualisieren:
sudo apt update && sudo apt -y upgradeInstallieren Sie nun zusätzliche Pakete, Bibliotheken und den Nvidia-Grafiktreiber. All dies wird benötigt, um die Software erfolgreich zu erstellen und auf dem Grafikprozessor auszuführen:
sudo apt -y install build-essential git gcc cmake make openssl libssl-dev libbz2-dev libreadline-dev libsqlite3-dev zlib1g-dev libncursesw5-dev libgdbm-dev libc6-dev zlib1g-dev libsqlite3-dev tk-dev libssl-dev openssl libffi-dev lzma liblzma-dev libbz2-devCUDA® 12.4 installieren
Neben dem Treiber müssen Sie auch das NVIDIA® CUDA® Toolkit installieren. Diese Anleitung wurde mit CUDA® 12.4 getestet, aber alles sollte auch mit CUDA® 12.2 funktionieren. Denken Sie jedoch daran, dass Sie die installierte Version angeben müssen, wenn Sie den Pfad zu den ausführbaren Dateien angeben.
Führen Sie den folgenden Befehl sequentiell aus:
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-ubuntu2204.pinsudo mv cuda-ubuntu2204.pin /etc/apt/preferences.d/cuda-repository-pin-600wget https://developer.download.nvidia.com/compute/cuda/12.4.0/local_installers/cuda-repo-ubuntu2204-12-4-local_12.4.0-550.54.14-1_amd64.debsudo dpkg -i cuda-repo-ubuntu2204-12-4-local_12.4.0-550.54.14-1_amd64.debsudo cp /var/cuda-repo-ubuntu2204-12-4-local/cuda-*-keyring.gpg /usr/share/keyrings/sudo apt-get update && sudo apt-get -y install cuda-toolkit-12-4Weitere Informationen zur Installation von CUDA® finden Sie in unserer Knowledge Base. Starten Sie nun den Server neu:
sudo shutdown -r nowPyEnv installieren
Es ist an der Zeit, ein einfaches Python-Versionskontrollprogramm namens PyEnv zu installieren. Es handelt sich dabei um einen deutlich verbesserten Fork des ähnlichen Projekts für Ruby (rbenv), der so konfiguriert wurde, dass er mit Python funktioniert. Es kann mit einem einzeiligen Skript installiert werden:
curl https://pyenv.run | bashNun müssen Sie am Ende der Skriptdatei, die bei der Anmeldung ausgeführt wird, einige Variablen hinzufügen. Die ersten drei Zeilen sind für den korrekten Betrieb von PyEnv verantwortlich, und die vierte wird für Poetry benötigt, das später installiert wird:
nano .bashrcexport PYENV_ROOT="$HOME/.pyenv"
[[ -d $PYENV_ROOT/bin ]] && export PATH="$PYENV_ROOT/bin:$PATH"
eval "$(pyenv init -)"
export PATH="/home/usergpu/.local/bin:$PATH"Übernehmen Sie die Einstellungen, die Sie vorgenommen haben:
source .bashrcInstallieren Sie Python Version 3.11:
pyenv install 3.11Erstellen Sie eine virtuelle Umgebung für Python 3.11:
pyenv local 3.11Poesie installieren
Das nächste Teil des Puzzles ist Poetry. Dies ist ein Analogon von pip für die Verwaltung von Abhängigkeiten in Python-Projekten. Der Autor von Poetry war es leid, sich ständig mit verschiedenen Konfigurationsmethoden wie setup.cfg, requirements.txt, MANIFEST.ini und anderen auseinanderzusetzen. Dies war der Auslöser für die Entwicklung eines neuen Werkzeugs, das eine pyproject.toml Datei verwendet, die alle grundlegenden Informationen über ein Projekt speichert, nicht nur eine Liste von Abhängigkeiten.
Poesie installieren:
curl -sSL https://install.python-poetry.org | python3 -PrivateGPT installieren
Nun, da alles bereit ist, können Sie das PrivateGPT-Repository klonen:
git clone https://github.com/imartinez/privateGPTRufen Sie das heruntergeladene Repository auf:
cd privateGPTFühren Sie die Installation der Abhängigkeiten mit Poetry aus und aktivieren Sie dabei zusätzliche Komponenten:
- ui - fügt der Backend-Anwendung eine Gradio-basierte Verwaltungsweboberfläche hinzu;
- embedding-huggingface - Unterstützung für die Einbettung von Modellen, die von HuggingFace heruntergeladen wurden;
- llms-llama-cpp - Unterstützung für die direkte Inferenz von Modellen im GGUF-Format hinzugefügt;
- vector-stores-qdrant - Hinzufügen der qdrant-Vektordatenbank.
poetry install --extras "ui embeddings-huggingface llms-llama-cpp vector-stores-qdrant"Setzen Sie Ihr HuggingFace-Zugangs-Token. Für zusätzliche Informationen lesen Sie bitte diesen Artikel:
export HF_TOKEN="YOUR_HUGGING_FACE_ACCESS_TOKEN"Führen Sie nun das Installationsskript aus, das automatisch das Modell und die Gewichte herunterlädt (Meta Llama 3.1 8B Instruct als Standard):
poetry run python scripts/setupMit dem folgenden Befehl wird llms-llama-cpp separat neu kompiliert, um die Unterstützung für NVIDIA® CUDA® zu aktivieren, damit die Arbeitslasten auf den Grafikprozessor verlagert werden können:
CUDACXX=/usr/local/cuda-12/bin/nvcc CMAKE_ARGS="-DGGML_CUDA=on -DCMAKE_CUDA_ARCHITECTURES=native" FORCE_CMAKE=1 pip install llama-cpp-python --no-cache-dir --force-reinstall --upgradeWenn Sie eine Fehlermeldung wie nvcc fatal : Unsupported gpu architecture 'compute_' erhalten, geben Sie einfach die genaue Architektur der GPU an, die Sie verwenden. Zum Beispiel: DCMAKE_CUDA_ARCHITECTURES=86 für NVIDIA® RTX™ 3090.
Der letzte Schritt vor dem Start ist die Installation der Unterstützung für asynchrone Aufrufe (async/await):
pip install asyncioPrivateGPT ausführen
Starten Sie PrivateGPT mit einem einzigen Befehl:
make runÖffnen Sie Ihren Webbrowser und gehen Sie auf die Seite http://[LeaderGPU_server_IP_address]:8001
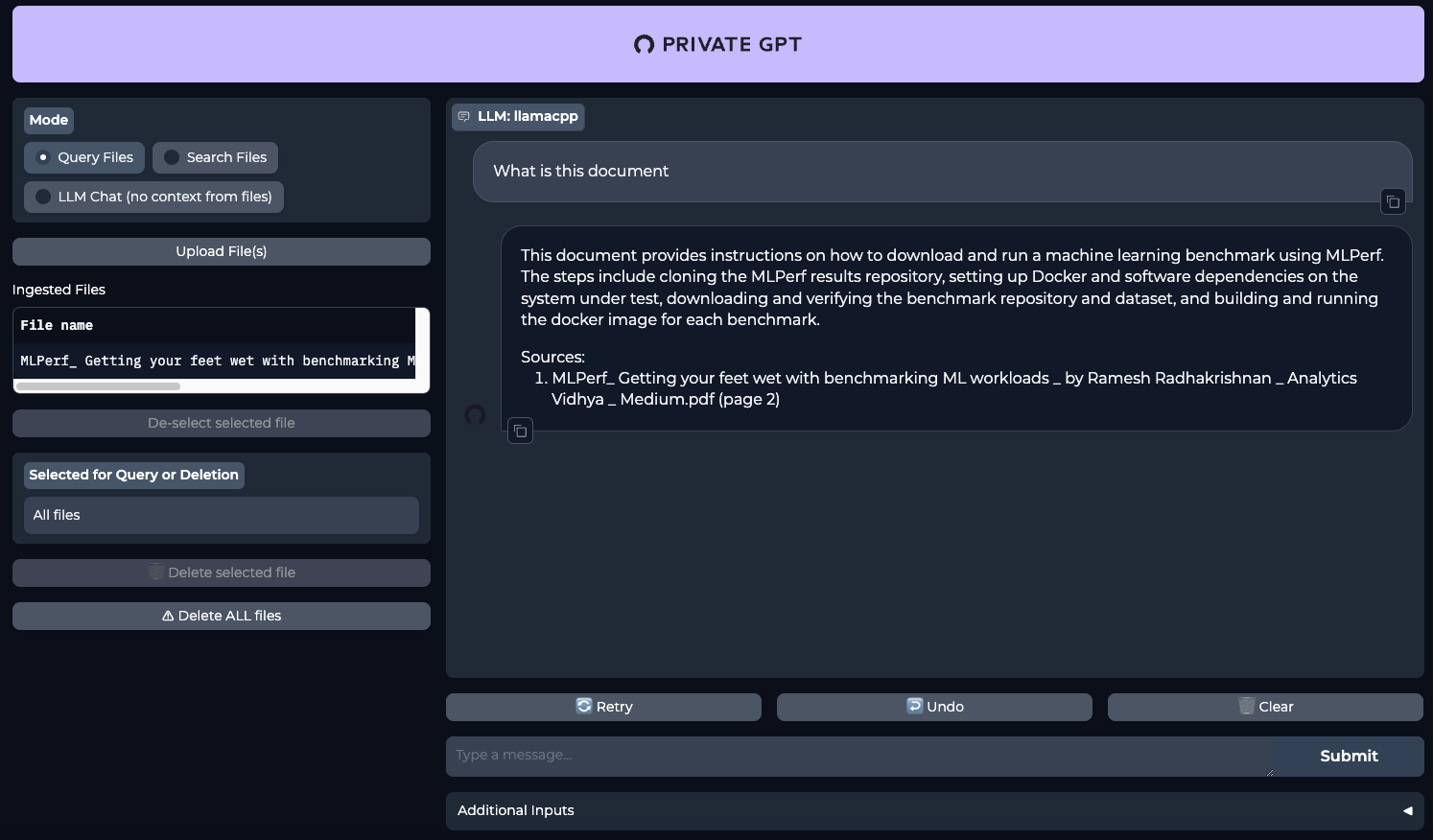
Siehe auch:
Aktualisiert: 04.01.2026
Veröffentlicht: 20.01.2025




