





KI-Anwendungsentwickler Langflow mit geringem Programmieraufwand
Die Softwareentwicklung hat sich in den letzten Jahren dramatisch weiterentwickelt. Moderne Programmierer haben jetzt Zugang zu Hunderten von Programmiersprachen und Frameworks. Neben den traditionellen imperativen und deklarativen Ansätzen hat sich eine neue und aufregende Methode zur Erstellung von Anwendungen entwickelt. Dieser innovative Ansatz macht sich die Leistungsfähigkeit neuronaler Netze zunutze und eröffnet den Entwicklern fantastische Möglichkeiten.
Die Menschen haben sich an KI-Assistenten in IDEs gewöhnt, die bei der automatischen Vervollständigung von Code helfen, und an moderne neuronale Netze, die problemlos Code für einfache Python-Spiele erzeugen. Es entstehen jedoch neue hybride Tools, die die Entwicklungslandschaft revolutionieren könnten. Ein solches Werkzeug ist Langflow.
Langflow dient mehreren Zwecken. Für professionelle Entwickler bietet es eine bessere Kontrolle über komplexe Systeme wie neuronale Netze. Für diejenigen, die mit der Programmierung nicht vertraut sind, ermöglicht es die Erstellung einfacher, aber praktischer Anwendungen. Diese Ziele werden mit verschiedenen Mitteln erreicht, auf die wir im Folgenden näher eingehen werden.
Neuronale Netze
Das Konzept eines neuronalen Netzes lässt sich für Benutzer vereinfachen. Stellen Sie sich eine Blackbox vor, die Eingabedaten und Parameter empfängt, die das Endergebnis beeinflussen. Diese Box verarbeitet die Eingaben mit Hilfe komplexer Algorithmen, die oft als "Magie" bezeichnet werden, und erzeugt Ausgabedaten, die dem Benutzer präsentiert werden können.
Das Innenleben dieser Blackbox hängt vom Design des neuronalen Netzes und den Trainingsdaten ab. Man muss sich darüber im Klaren sein, dass Entwickler und Benutzer nie eine 100-prozentige Sicherheit der Ergebnisse erreichen können. Im Gegensatz zur traditionellen Programmierung, bei der 2 + 2 immer gleich 4 ist, kann ein neuronales Netz diese Antwort mit 99 %iger Sicherheit geben, wobei immer eine Fehlerspanne bleibt.
Die Kontrolle über den "Denk"-Prozess eines neuronalen Netzes ist indirekt. Wir können nur bestimmte Parameter einstellen, z. B. die "Temperatur". Dieser Parameter bestimmt, wie kreativ oder eingeschränkt das neuronale Netz bei seinem Ansatz sein kann. Ein niedriger Temperaturwert schränkt das Netz auf einen eher formalen, strukturierten Ansatz für Aufgaben und Lösungen ein. Umgekehrt gewähren hohe Temperaturwerte dem Netz mehr Freiheit, was dazu führen kann, dass es sich auf weniger zuverlässige Fakten stützt oder sogar fiktive Informationen erstellt.
Dieses Beispiel verdeutlicht, wie die Benutzer das Endergebnis beeinflussen können. Für die traditionelle Programmierung stellt diese Ungewissheit eine große Herausforderung dar - Fehler können unerwartet auftreten, und bestimmte Ergebnisse werden unvorhersehbar. Diese Unvorhersehbarkeit ist jedoch in erster Linie ein Problem für Computer und nicht für Menschen, die sich auf unterschiedliche Ergebnisse einstellen und diese interpretieren können.
Wenn die Ausgabe eines neuronalen Netzes für einen Menschen bestimmt ist, ist die spezifische Formulierung, mit der sie beschrieben wird, im Allgemeinen weniger wichtig. Wenn der Kontext gegeben ist, kann der Mensch verschiedene Ergebnisse aus der Sicht der Maschine richtig interpretieren. Während Begriffe wie "positiver Wert", "erzieltes Ergebnis" oder "positive Entscheidung" für einen Menschen in etwa das Gleiche bedeuten könnten, hätte die herkömmliche Programmierung mit dieser Flexibilität ihre Schwierigkeiten. Sie müsste alle möglichen Antwortvarianten berücksichtigen, was nahezu unmöglich ist.
Wird die weitere Verarbeitung hingegen an ein anderes neuronales Netz übergeben, kann dieses das erhaltene Ergebnis richtig verstehen und verarbeiten. Auf dieser Grundlage kann es dann, wie bereits erwähnt, mit einem gewissen Maß an Sicherheit seine eigene Schlussfolgerung ziehen.
Niedriger Code
Die meisten Programmiersprachen erfordern das Schreiben von Code. Programmierer erstellen die Logik für jeden Teil einer Anwendung in ihren Köpfen und beschreiben sie dann mit sprachspezifischen Ausdrücken. Dieser Prozess bildet einen Algorithmus: eine klare Abfolge von Aktionen, die zu einem bestimmten, vorher festgelegten Ergebnis führen. Dies ist eine komplexe Aufgabe, die erhebliche geistige Anstrengung und ein tiefes Verständnis für die Möglichkeiten der Sprache erfordert.
Es besteht jedoch keine Notwendigkeit, das Rad neu zu erfinden. Viele Probleme, mit denen moderne Entwickler konfrontiert sind, wurden bereits auf verschiedene Weise gelöst. Einschlägige Codeschnipsel sind oft auf StackOverflow zu finden. Modernes Programmieren lässt sich mit dem Zusammensetzen eines Ganzen aus Teilen verschiedener Baukästen vergleichen. Das Lego-System bietet ein erfolgreiches Modell, da es verschiedene Teilesätze standardisiert hat, um Kompatibilität zu gewährleisten.
Die Methode der Low-Code-Programmierung folgt einem ähnlichen Prinzip. Verschiedene Codeteile werden so modifiziert, dass sie nahtlos zusammenpassen, und werden den Entwicklern als fertige Blöcke präsentiert. Jeder Block kann Dateneingaben und -ausgaben haben. Die Dokumentation gibt an, welche Aufgabe jeder Blocktyp löst und in welchem Format er Daten annimmt oder ausgibt.
Durch die Verknüpfung dieser Blöcke in einer bestimmten Reihenfolge können Entwickler den Algorithmus einer Anwendung bilden und ihre Funktionslogik klar darstellen. Das vielleicht bekannteste Beispiel für diese Programmiermethode ist die Schildkrötengrafikmethode, die häufig in der Ausbildung verwendet wird, um Programmierkonzepte einzuführen und algorithmisches Denken zu entwickeln.
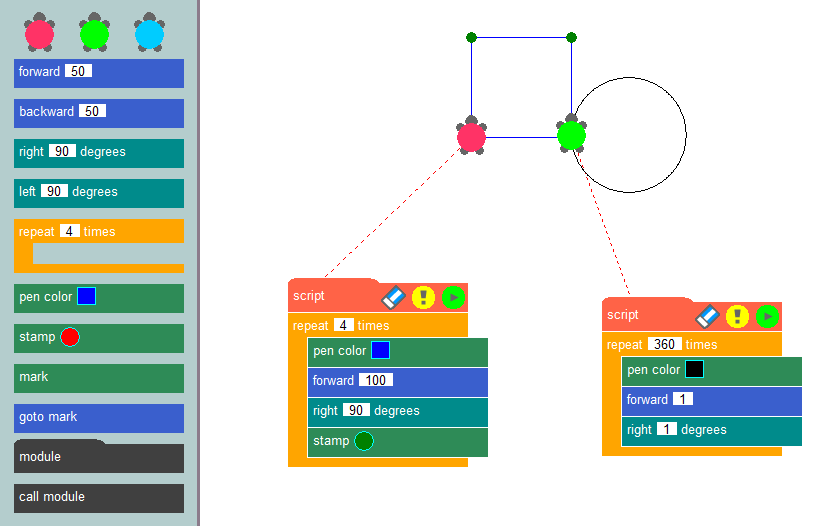
Das Wesen dieser Methode ist einfach: Sie zeichnet Bilder auf dem Bildschirm mit Hilfe einer virtuellen Schildkröte, die eine Spur hinterlässt, während sie über die Leinwand krabbelt. Mithilfe von vorgefertigten Blöcken, wie z. B. dem Bewegen einer bestimmten Anzahl von Pixeln, dem Drehen in bestimmten Winkeln oder dem Heben und Senken des Stifts, können Entwickler Programme erstellen, die ihre gewünschten Bilder zeichnen. Die Erstellung von Anwendungen mit einem Low-Code-Konstruktor ähnelt der Schildkrötengrafik, ermöglicht es den Benutzern jedoch, eine Vielzahl von Problemen zu lösen, die sich nicht auf das Zeichnen auf einer Leinwand beschränken.
Diese Methode wurde am besten in IBMs Programmierwerkzeug Node-RED umgesetzt. Es wurde als universelles Mittel entwickelt, um den gemeinsamen Betrieb verschiedener Geräte, Online-Dienste und APIs zu gewährleisten. Das Äquivalent zu Codeschnipseln waren Knoten aus der Standardbibliothek (Palette).

Die Fähigkeiten von Node-RED können durch die Installation von Add-Ons oder die Erstellung benutzerdefinierter Knoten, die bestimmte Datenaktionen ausführen, erweitert werden. Die Entwickler platzieren Knoten aus der Palette auf dem Desktop und bauen Beziehungen zwischen ihnen auf. Durch diesen Prozess entsteht die Logik der Anwendung, wobei die Visualisierung dazu beiträgt, die Übersichtlichkeit zu wahren.
Wenn man diesem Konzept neuronale Netze hinzufügt, entsteht ein faszinierendes System. Anstatt Daten mit bestimmten mathematischen Formeln zu verarbeiten, können Sie sie in ein neuronales Netz einspeisen und die gewünschte Ausgabe festlegen. Obwohl die Eingabedaten jedes Mal leicht variieren können, bleiben die Ergebnisse für die Interpretation durch Menschen oder andere neuronale Netze geeignet.
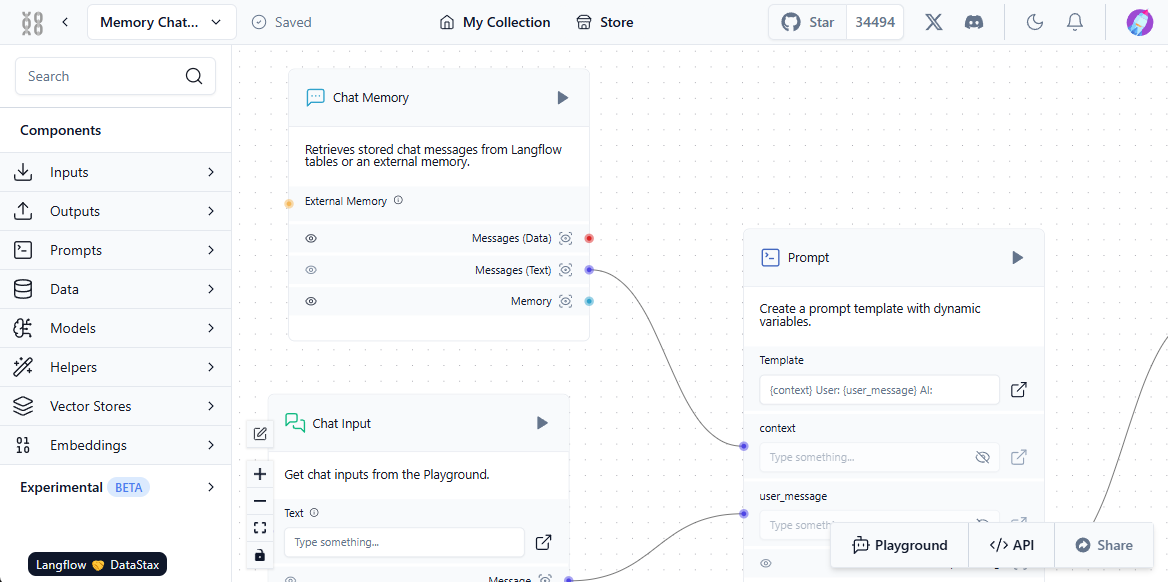
Retrieval Augmented Generation (RAG)
Die Genauigkeit der Daten in großen Sprachmodellen ist ein dringendes Problem. Diese Modelle stützen sich ausschließlich auf das beim Training gewonnene Wissen, das von der Relevanz der verwendeten Datensätze abhängt. Folglich kann es bei großen Sprachmodellen an ausreichend relevanten Daten mangeln, was zu falschen Ergebnissen führen kann.
Um dieses Problem zu lösen, sind Methoden zur Datenaktualisierung erforderlich. Wenn es neuronalen Netzen ermöglicht wird, Kontext aus zusätzlichen Quellen, wie z. B. Websites, zu extrahieren, kann die Qualität der Antworten erheblich verbessert werden. Genau auf diese Weise funktioniert RAG (Retrieval-Augmented Generation). Zusätzliche Daten werden in Vektordarstellungen umgewandelt und in einer Datenbank gespeichert.
Im Betrieb können neuronale Netzmodelle Benutzeranfragen in Vektordarstellungen umwandeln und diese mit den in der Datenbank gespeicherten vergleichen. Wenn ähnliche Vektoren gefunden werden, werden die Daten extrahiert und für die Erstellung einer Antwort verwendet. Vektordatenbanken sind schnell genug, um dieses Verfahren in Echtzeit zu unterstützen.
Damit dieses System korrekt funktioniert, muss eine Interaktion zwischen dem Benutzer, dem neuronalen Netzmodell, externen Datenquellen und der Vektordatenbank hergestellt werden. Langflow vereinfacht diese Einrichtung durch seine visuelle Komponente - der Benutzer baut einfach Standardblöcke und "verknüpft" sie, wodurch ein Pfad für den Datenfluss entsteht.
Der erste Schritt besteht darin, die Vektordatenbank mit relevanten Quellen zu füllen. Dazu können Dateien von einem lokalen Computer oder Webseiten aus dem Internet gehören. Hier ist ein einfaches Beispiel für das Laden von Daten in die Datenbank:
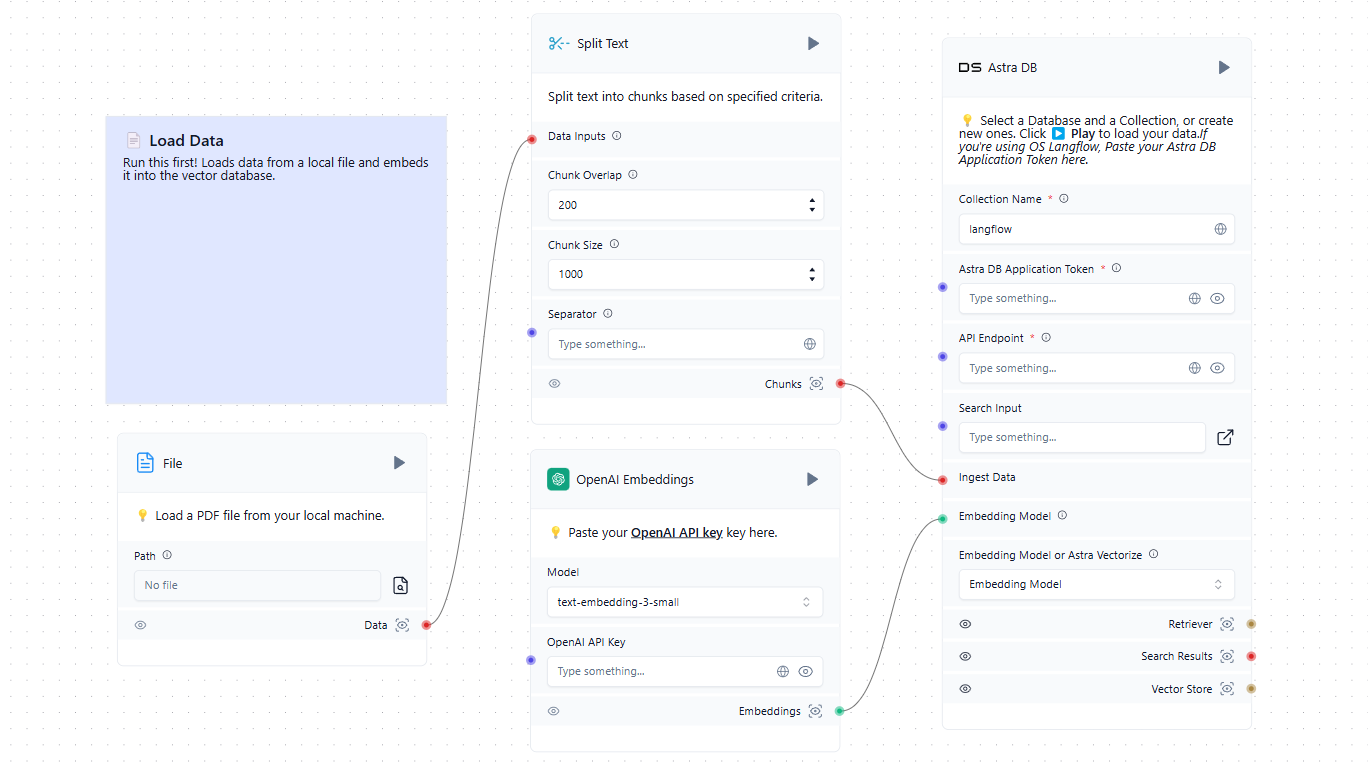
Nun, da wir neben dem trainierten LLM auch eine Vektordatenbank haben, können wir sie in das allgemeine Schema einbinden. Wenn ein Benutzer eine Anfrage im Chat stellt, wird gleichzeitig eine Eingabeaufforderung erstellt und die Vektordatenbank abgefragt. Wenn ähnliche Vektoren gefunden werden, werden die extrahierten Daten geparst und als Kontext zu dem gebildeten Prompt hinzugefügt. Das System sendet dann eine Anfrage an das neuronale Netz und gibt die erhaltene Antwort an den Nutzer im Chat aus.
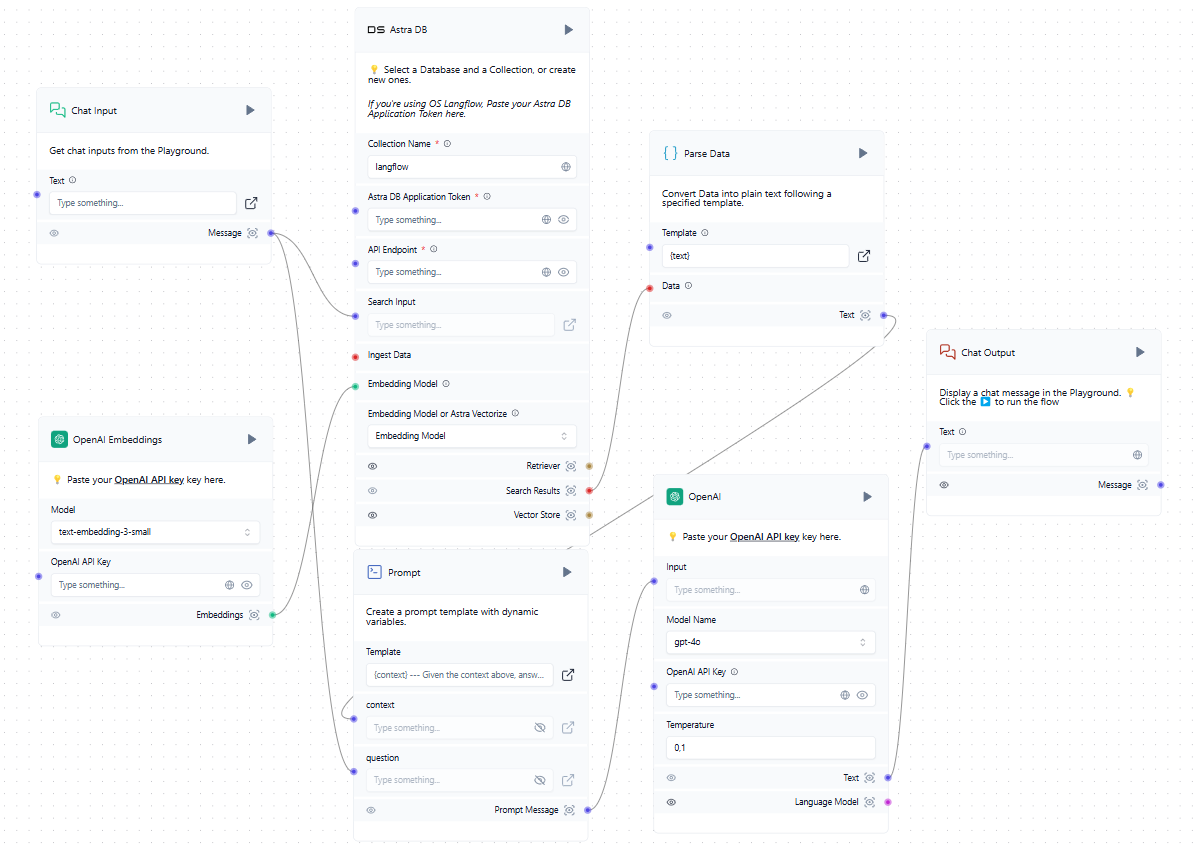
Während im Beispiel Cloud-Dienste wie OpenAI und AstraDB erwähnt werden, können Sie alle kompatiblen Dienste verwenden, einschließlich derer, die lokal auf LeaderGPU-Servern bereitgestellt werden. Wenn Sie die von Ihnen benötigte Integration in der Liste der verfügbaren Blöcke nicht finden können, können Sie sie entweder selbst schreiben oder eine von jemand anderem erstellte hinzufügen.
Schnellstart
System vorbereiten
Die einfachste Art, Langflow einzusetzen, ist in einem Docker-Container. Um den Server einzurichten, installieren Sie zunächst die Docker Engine. Aktualisieren Sie dann sowohl den Paket-Cache als auch die Pakete auf ihre neuesten Versionen:
sudo apt update && sudo apt -y upgradeInstallieren Sie zusätzliche Pakete, die von Docker benötigt werden:
sudo apt -y install apt-transport-https ca-certificates curl software-properties-commonLaden Sie den GPG-Schlüssel herunter, um das offizielle Docker-Repository hinzuzufügen:
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpgFügen Sie das Repository zur APT hinzu, indem Sie den Schlüssel verwenden, den Sie zuvor heruntergeladen und installiert haben:
echo "deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/nullAktualisieren Sie die Paketliste:
sudo apt updateUm sicherzustellen, dass Docker aus dem neu hinzugefügten Repository und nicht aus dem System-Repository installiert wird, können Sie den folgenden Befehl ausführen:
apt-cache policy docker-ceDocker-Engine installieren:
sudo apt install docker-ceÜberprüfen Sie, ob Docker erfolgreich installiert wurde und der entsprechende Daemon läuft und den Status active (running) hat:
sudo systemctl status docker● docker.service - Docker Application Container Engine
Loaded: loaded (/lib/systemd/system/docker.service; enabled; vendor preset>
Active: active (running) since Mon 2024-11-18 08:26:35 UTC; 3h 27min ago
TriggeredBy: ● docker.socket
Docs: https://docs.docker.com
Main PID: 1842 (dockerd)
Tasks: 29
Memory: 1.8G
CPU: 3min 15.715s
CGroup: /system.slice/docker.service
Erstellen und Ausführen
Alles ist bereit, um einen Docker-Container mit Langflow zu erstellen und auszuführen. Es gibt jedoch eine Einschränkung: Zum Zeitpunkt der Erstellung dieses Leitfadens hat die neueste Version (mit dem Tag v1.1.0) einen Fehler und lässt sich nicht starten. Um dieses Problem zu vermeiden, verwenden wir die vorherige Version, v1.0.19.post2, die direkt nach dem Herunterladen einwandfrei funktioniert.
Der einfachste Ansatz ist der Download des Projekt-Repositorys von GitHub:
git clone https://github.com/langflow-ai/langflowNavigieren Sie zu dem Verzeichnis, das die Beispielkonfiguration für die Bereitstellung enthält:
cd langflow/docker_exampleNun müssen Sie zwei Dinge tun. Erstens ändern Sie das Release-Tag, so dass eine funktionierende Version (zum Zeitpunkt der Erstellung dieser Anleitung) erstellt wird. Zweitens fügen Sie eine einfache Autorisierung hinzu, damit niemand das System benutzen kann, ohne Login und Passwort zu kennen.
Öffnen Sie die Konfigurationsdatei:
sudo nano docker-compose.ymlanstelle der folgenden Zeile:
image: langflowai/langflow:latestGeben Sie die Version anstelle des Tags latest an:
image: langflowai/langflow:v1.0.19.post2Sie müssen auch drei Variablen in den Abschnitt environment aufnehmen:
- LANGFLOW_AUTO_LOGIN=false
- LANGFLOW_SUPERUSER=admin
- LANGFLOW_SUPERUSER_PASSWORD=your_secure_passwordDie erste Variable deaktiviert den Zugriff auf die Webschnittstelle ohne Autorisierung. Die zweite fügt den Benutzernamen hinzu, der Systemadministratorrechte erhalten soll. Die dritte fügt das entsprechende Passwort hinzu.
Wenn Sie vorhaben, die Datei docker-compose.yml in einem Versionskontrollsystem zu speichern, sollten Sie das Passwort nicht direkt in diese Datei schreiben. Erstellen Sie stattdessen eine separate Datei mit der Erweiterung .env im selben Verzeichnis und speichern Sie den Variablenwert dort.
LANGFLOW_SUPERUSER_PASSWORD=your_secure_passwordIn der Datei docker-compose.yml können Sie nun auf eine Variable verweisen, anstatt direkt ein Kennwort anzugeben:
LANGFLOW_SUPERUSER_PASSWORD=${LANGFLOW_SUPERUSER_PASSWORD}Um zu verhindern, dass die Datei *.env versehentlich auf GitHub veröffentlicht wird, denken Sie daran, sie zu .gitignore hinzuzufügen. So ist Ihr Passwort vor unerwünschtem Zugriff einigermaßen sicher.
Jetzt müssen wir nur noch unseren Container bauen und ihn ausführen:
sudo docker compose upÖffnen Sie die Webseite http://[LeaderGPU_IP_address]:7860, und Sie werden das Autorisierungsformular sehen:
Nach Eingabe Ihres Logins und Passworts gewährt Ihnen das System Zugriff auf die Weboberfläche, auf der Sie Ihre eigenen Anwendungen erstellen können. Für eine ausführlichere Anleitung empfehlen wir, die offizielle Dokumentation zu konsultieren. Sie enthält Einzelheiten zu verschiedenen Umgebungsvariablen, die eine einfache Anpassung des Systems an Ihre Bedürfnisse ermöglichen.
Siehe auch:
Aktualisiert: 04.01.2026
Veröffentlicht: 22.01.2025




