





Sollte Tensorflow™ kompiliert werden?
In nur zwei Jahren hat sich Tensorflow™ zu einer der beliebtesten Bibliotheken für tiefes maschinelles Lernen entwickelt. Es ist wichtig, bei der Arbeit an Tensorflow™-Projekten die höchstmögliche Leistung zu erreichen, genau wie bei der Entwicklung jedes anderen Softwareprodukts.
Laut Google-Empfehlung lässt sich die Geschwindigkeit der Berechnungen am effektivsten erhöhen, wenn statt eines vorkompilierten Pakets der Tensorflow™-Bibliothek eine direkt aus dem Quellcode kompilierte Tensorflow™-Version verwendet wird. Kürzlich wurde eine Studie durchgeführt, um die von Google vorgeschlagene Methode zu testen. Dabei wurden dieselben Projekte mit Tensorflow™ ohne die Unterstützung der CUDA®-Plattform auf drei verschiedene Arten installiert:
- Verwendung eines vorkompilierten Pakets;
- Direkt aus dem Quellcode kompiliert ohne unterstützende CPU-Befehle;
- Direkt aus dem Quellcode kompiliert mit Unterstützung von CPU-Befehlen (AVX, AVX2 und FMA usw.).
Es wurden auch Tests der Tensorflow™-Bibliothek mit Unterstützung für die CUDA®-Plattform durchgeführt. Die folgenden Testergebnisse wurden als Benchmarks herangezogen:
- Tests mit echten Daten. Es wurde ein Netzwerk vom Typ Inception-ResNet-v2 genommen und mit Hilfe des FaceScrub-Datensatzes (http://vintage.winklerbros.net/facescrub.html) trainiert, um das Geschlecht von Personen zu erkennen.
- Synthetische Tests von der offiziellen TensorFlow™-Website. Als neuronales Netzmodell wurde Inception V3 verwendet (https://www.tensorflow.org/lite/performance/measurement).
Die Tests wurden auf dem Server mit der folgenden Konfiguration durchgeführt (www.leadergpu.de):
- GPU: NVIDIA® Tesla® P100 (16 GB)
- CPU: 2 x Intel® Xeon® E5-2630v4 2.2 GHz
- RAM: 128 GB
- SSD: 960 GB
- Ports: 40 Gbps
- OS: CentOS 7
- Python 2.7
- TensorFlow™ 1.3
Befehle zur Installation von Tensorflow™ ohne CUDA®-Unterstützung:
Installation von Tensorflow™ aus einem vorkompilierten Paket:
# pip install tensorflowInstallation von Tensorflow™ – direkt aus dem Quellcode kompiliert:
# git clone https://github.com/tensorflow/tensorflow
# cd tensorflow
# git checkout r1.3
# ./configure-
für die Kompilierung ohne Unterstützung für CPU-Befehle:
# bazel build -c opt //tensorflow/tools/pip_package:build_pip_package -
für die Kompilierung mit Unterstützung für CPU-Befehle:
# bazel build -c opt --copt=-mavx --copt=-mavx2 --copt=-mfma --copt=-mfpmath=both --copt=-msse4.1 --copt=-msse4.2 //tensorflow/tools/pip_package:build_pip_package bazel-bin/tensorflow/tools/pip_package/build_pip_package /tmp/tensorflow_pkg # pip install /tmp/tensorflow_pkg/1.3.0-cp27-cp27mu-linux_x86_64.whl
Tests mit echten Daten und synthetischen Daten ohne CUDA-Unterstützung
Befehle zum Starten eines Netzes für Tests mit echten Daten:
# cd gender_net
# python download_data.py
# python convert_data_FS.py
# time python model_FS_mulGPU_v3.pyBefehle zur Durchführung von Tests mit synthetischen Daten:
# mkdir ~/Anaconda
# cd ~/Anaconda
# git clone https://github.com/tensorflow/benchmarks.git
# cd ~/Anaconda/benchmarks/scripts/tf_cnn_benchmarks
# python tf_cnn_benchmarks.py --devicecpu model --inception3 --batch_size 32 --data_format NHWC --num_batches 40
Test von Tensorflow™ – installiert aus einem vorkompilierten Paket:
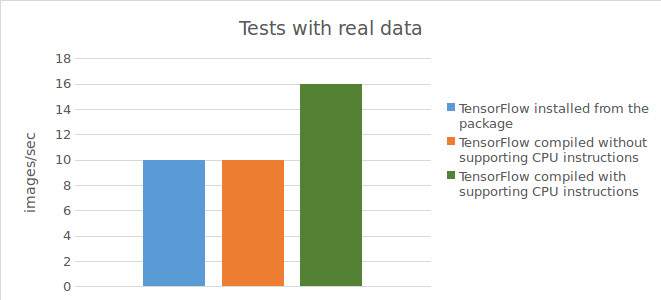
Ergebnis für Tests mit echten Daten:
10 images / sec;
Laufzeit des Testskripts
= 20m55s.
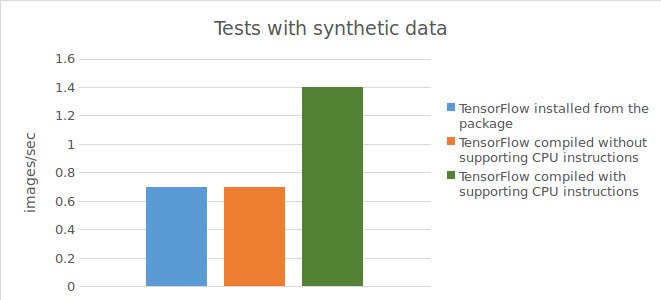
Ergebnis für Tests mit synthetischen Daten:
0,73 images/sec;
Laufzeit des Testskripts
= 36m25s.
Test von Tensorflow™ – direkt aus dem Quellcode kompiliert ohne die Unterstützung von CPU-Befehlen:
Ergebnis für Tests mit echten Daten:
10 images/sec;
Laufzeit des Testskripts
= 20m55s.
Ergebnis für Tests mit synthetischen Daten:
0,74 images/sec;
Laufzeit des Testskripts
= 36m21s.
Test von Tensorflow™ – direkt aus dem Quellcode kompiliert mit Unterstützung für CPU-Befehle:
Ergebnis für Tests mit echten Daten:
15-16 images/sec;
Laufzeit des Testskripts
= 14m13s.
Ergebnis für Tests mit synthetischen Daten:
1,44 images/sec;
Laufzeit des Testskripts
= 18m40s.
Nachstehend finden Sie eine Tabelle mit den Testergebnissen.
Befehle für die Installation von Tensorflow™ mit CUDA®-Unterstützung:
Installation von Tensorflow™ aus einem vorkompilierten Paket:
# pip install tensorflowInstallation von Tensorflow™ – direkt aus dem Quellcode kompiliert:
# git clone https://github.com/tensorflow/tensorflow
# cd tensorflow
# git checkout r1.3
#./configure
# bazel build -c opt --copt=-mavx --copt=-mavx2 --copt=-mfma --copt=-mfpmath=both --copt=-msse4.1 --copt=-msse4.2 --config=cuda //tensorflow/tools/pip_package:build_pip_package
bazel-bin/tensorflow/tools/pip_package/build_pip_package /tmp/tensorflow_pkg
# pip install /tmp/tensorflow_pkg/1.3.0-cp27-cp27mu-linux_x86_64.whlDie Befehle zum Starten von Netzen ähneln den Befehlen aus den vorangegangenen Tests, mit Ausnahme des Befehls zum Ausführen des Skripts, um das Lernen des Netzes mit synthetischen Daten zu starten:
# python tf_cnn_benchmarks.py --num_gpus=1 --model inception3 --batch_size 32Tests mit echten Daten und synthetischen Daten mit Unterstützung für CUDA
Test von Tensorflow™ – installiert aus einem vorkompilierten Paket:
Ergebnis für Tests mit echten Daten:
214 images/sec.
Ergebnis für Tests mit synthetischen Daten:
126,33 images/sec.
Test von Tensorflow™ – direkt aus dem Quellcode kompiliert mit Unterstützung für CPU-Befehle:
Ergebnis für Tests mit echten Daten:
215 images/sec.
Ergebnis für Tests mit synthetischen Daten:
126,34 images/sec.
Zusammenfassend lässt sich sagen, dass die Verwendung von Tensorflow™, das direkt aus dem Quellcode kompiliert wurde (mit Unterstützung für CPU-Befehle), zu einer deutlichen Beschleunigung (1,5-mal schneller bei echten Daten und 2-mal schneller bei synthetischen Daten) führt, wenn Berechnungen auf der CPU durchgeführt werden. Bei Verwendung einer GPU konnte jedoch durch die Verwendung von Tensorflow™, das direkt aus dem Quellcode kompiliert wurde, keine Verbesserung der Ergebnisse im Vergleich zum aus dem vorkompilierten Paket installierten Tensorflow™ erzielt werden.